PDF校正をAIで自動化する方法 ― テキスト抽出から差分レポートまでの実践パイプライン
PDF文書のAI校正を実践するための4ステップパイプラインを解説。テキスト抽出の技術選定からAI校正、差分レポート作成まで、PDF特有の課題を解決する具体的な方法を紹介します。
「このPDF、誰か校正してくれない?」と言われて、PDFを印刷し、赤ペンで修正箇所を書き込み、それを写真に撮って戻す。 2026年になった今でも、こうした非効率な校正フローが多くの現場で残っています。WordやテキストファイルならAI校正ツールに直接入力すれば済む話が、PDFになった途端に手が止まる。その理由は、PDFが「見た目を固定するためのフォーマット」であり、テキストを自由に編集することを前提としていないからです。
しかし2025年後半から、この状況は大きく変わりつつあります。マルチモーダルLLMがPDFを直接読み取れるようになり、日本語特化の校正ツールもPDF対応を進めています。この記事では、PDF校正をAIで自動化するための具体的なパイプラインを、テキスト抽出から差分レポート作成まで一気通貫で解説します。
なぜPDFの校正は「特別に難しい」のか
「PDFの校正って、テキストをコピペしてAIに入れればいいのでは?」――この発想は半分正解で半分間違いです。テキストをコピーできるPDFもありますが、コピーした時点でレイアウト情報は失われます。段組みの文章は順序が入れ替わり、表のデータはバラバラになり、ヘッダーやフッターが本文に混入します。
PDFの校正が難しい根本的な理由は、PDFの内部構造にあります。PDFは文字を「座標」で管理しています。「この文字をX座標100、Y座標200の位置に描画する」という命令の集合体がPDFの実体です。人間が読むような「段落」「文」「単語」といった構造は、PDF内部には存在しません。
この構造上の制約が、以下の3つの問題を生みます。
問題1: テキスト抽出の精度が不安定
同じ「こんにちは」という5文字でも、PDFの作り方によって抽出結果が変わります。文字間のスペース情報が欠落して「こ ん に ち は」になったり、フォント情報の問題で文字化けしたりします。特に日本語PDFでは、縦書き、ルビ(振り仮名)、異体字の処理が課題になります。
問題2: レイアウト構造の解釈が困難
2段組みのPDFで左列と右列のテキストが混ざる、表のセル内テキストが行単位でバラバラに抽出される、図のキャプションが本文に紛れ込む。これらはすべて、PDFが「見た目」の情報しか持たず、「文書構造」の情報を持たないことに起因します。
問題3: 修正を元PDFに反映しにくい
仮にAIが誤りを検出できても、その修正をPDFに直接反映するのが難しい。PDFは基本的に「出力用フォーマット」であり、修正は原稿ファイル(Word、InDesignなど)に対して行い、再度PDFを書き出すのが正しいワークフローです。
PDF校正の本質
PDF校正で最も重要なのは「テキスト抽出の精度」です。抽出の精度が低いまま AI に校正させると、元の文書に存在しない誤りを「検出」したり、実際の誤りを見逃したりします。テキスト抽出の品質確認を省略すると、校正工程全体が無意味になるリスクがあります。
PDF校正の「3層問題」― 失敗しないための診断フレームワーク
私たちがPDF校正の自動化を支援する中で整理したのが、「3層問題」というフレームワークです。PDF校正がうまくいかない原因は、必ずこの3つの層のいずれかにあります。
第1層: テキスト層(文字を正しく取り出せるか)
最も基礎的な層です。PDFからテキストを正確に抽出できなければ、その先の校正は成り立ちません。テキスト層の品質は、PDFの作成方法で大きく変わります。
- フォント埋め込みPDF: テキスト抽出精度が高い。Word→PDF変換で作られたPDFの多くがこれに該当
- アウトラインPDF: 文字がすべて図形に変換されているため、テキスト抽出は不可能。OCRが必須
- スキャンPDF: 紙をスキャンした画像なので、OCRの精度に完全に依存する
第2層: 構造層(レイアウトを正しく解釈できるか)
テキストが正しく抽出できても、文章の構造が壊れていれば校正はできません。構造層で問題になるのは以下のケースです。
- 段組み: 左列の最終行と右列の最初の行が繋がって認識される
- 表組み: セルの区切りが失われ、行単位のテキストとして抽出される
- ヘッダー・フッター・ページ番号: 本文テキストに混入する
- 脚注・注釈: 本文のどの位置に対応するか判断できない
第3層: 意味層(内容を正しくチェックできるか)
テキストと構造が正しく取得できて、ようやく意味レベルの校正が可能になります。この層は通常の文章チェックと同じ領域ですが、PDF特有の注意点があります。
- 改ページによる文の分断: ページをまたぐ文が途中で切れて、文法チェックが誤動作する
- レイアウト依存の表現: 「上記の表」「左図参照」などの参照表現が、テキストだけでは検証できない
- 版管理: 同じ文書の異なるバージョン間で、意図的な変更と誤りの区別がつきにくい
このフレームワークを使って自社のPDF校正の課題を診断すると、「どこに手を打てば効果が出るか」が明確になります。テキスト層に問題があるならOCR精度の改善が先決ですし、構造層が問題ならレイアウト解析ツールの導入を検討すべきです。
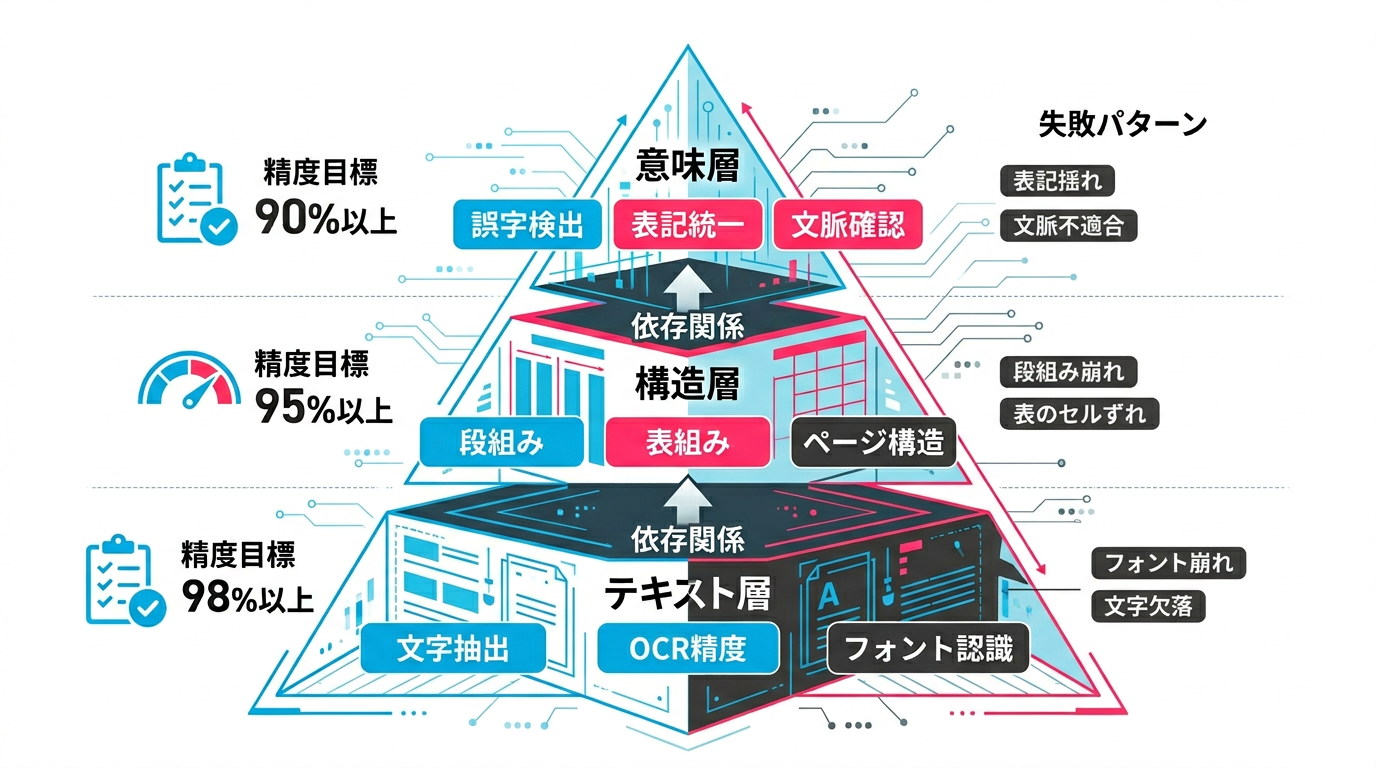
図2: PDF校正の「3層問題」診断フレームワーク
PDF AI校正の4ステップパイプライン
3層問題を理解した上で、実際にPDF校正をAIで自動化するための4ステップパイプラインを設計しました。各ステップでのツール選定と品質チェックのポイントを具体的に解説します。
Step 1: テキスト抽出 ― PDF種別に応じた方法を選ぶ
テキスト抽出の方法は、PDFの種別によって最適解が異なります。
ネイティブPDF(テキスト埋め込みあり)の場合
フォントとテキスト情報が埋め込まれているPDFでは、OCRを使わずにテキストを直接抽出できます。処理速度が速く、精度も高いのがメリットです。
2026年現在、テキスト抽出ライブラリの中ではPyMuPDF(fitz)が処理速度と精度のバランスで優れています。0.12秒で抽出が完了し、表や段組みのレイアウトも比較的正確に解析できます。pdfplumberは表データの抽出に特化しており、表の多い文書ではこちらが有利です。
スキャンPDF・画像PDFの場合
紙の文書をスキャンしたPDFや、画像として作成されたPDFでは、OCR(光学文字認識)が必須です。日本語OCRの精度は2025年以降大きく向上しており、活字であれば99%以上の精度が期待できます。ただし、手書き文字や低解像度のスキャンでは精度が大幅に低下します。
ここで注目すべきは、マルチモーダルLLMの進化です。Claude、GPT、GeminiなどのLLMはPDFを直接入力として受け付けるようになっており、従来のOCR→テキスト抽出という二段階の工程を一気に省略できます。テキストベースのPDFではGPTが98%、Claudeが97%、Geminiが96%の精度を達成しています。スキャンPDFではGeminiがビジョン機能の統合により94%の精度でリードしています。
テキスト抽出の品質チェック
テキスト抽出後は必ず「サンプルチェック」を行ってください。PDF全体から3〜5ページを選び、抽出テキストと原文を目視で比較します。文字化け、スペースの混入、段組みの混在がないか確認し、精度が95%を下回る場合は抽出方法の見直しが必要です。
Step 2: AI校正 ― 専用ツールとLLMの使い分け
テキストが正しく抽出できたら、AI校正に進みます。ここでの選択肢は大きく2つです。
選択肢A: 日本語特化の校正ツール
日本語の校正に特化したツールは、表記ゆれや敬語の誤用など、日本語固有の問題を高精度で検出できます。AI文章校正ツールの選び方で詳しく解説していますが、PDF対応のツールは限られています。
PDF校正に直接対応しているのは、wordrabbit(Business Team以上のプラン)とTypoless(+Plusプラン)の2つが主要な選択肢です。wordrabbitは複雑なレイアウト(縦書き、段組み、ルビ)に対応し、テキスト抽出精度98%を実現しています。Typolessは朝日新聞社の40年分の校正ノウハウをベースにしており、2024年10月にPDF対応を開始しました。OCRエンジンを全面的に再構築し、縦書きの認識精度が大幅に向上しています。
選択肢B: LLMへの直接入力
Claude、GPT、GeminiなどのLLMにPDFを直接アップロードして校正指示を出す方法です。専用ツールと比較した利点は、「何をチェックするか」をプロンプトで柔軟に指定できることです。
たとえば製薬業界のPDF校正であれば「薬機法に抵触する可能性のある表現を指摘してください」、法務文書であれば「契約条件の矛盾や曖昧な表現を検出してください」といった、業界特有のチェックが可能です。校正と校閲の違いで解説している「校閲」に近い、内容面のチェックはLLMが得意とする領域です。
ただし注意点があります。LLMで校正する場合、重要なのは「校正」「校閲」「編集」「添削」の区別をプロンプトで明確にすることです。曖昧な指示では、勝手に文章を書き換えてしまうリスクがあります。校正の目的(誤字脱字の検出のみか、内容面のチェックも含むか)を明示してください。
Step 3: 差分レポート ― 修正箇所を可視化する
AI校正の結果を「どう報告するか」は、現場への定着を左右する重要なポイントです。校正結果を単にテキストで列挙しても、元のPDFのどこに該当するのかが分からなければ、修正作業が非効率になります。
差分レポートの形式は主に3つあります。
- 注釈付きPDF: 元のPDFに直接コメントや赤字を入れる形式。Adobe Acrobat Proのコメント機能や、wordrabbitのAdobe Acrobatコメント出力機能が使えます。校正者にとって最も直感的
- 修正一覧表(Excel/CSV): ページ番号、修正箇所、修正前テキスト、修正後テキスト、指摘理由を一覧にした形式。管理職への報告や、修正の承認フローに適しています
- 差分ハイライト: 修正前後のPDFを比較し、変更箇所を色分けして表示する形式。いきなりPDF差分チェック(3,960円)やAdobe Acrobat Proのファイル比較機能が対応しています
私たちが推奨するのは、注釈付きPDF+修正一覧表の併用です。現場の校正者には注釈付きPDFで修正箇所を直感的に確認してもらい、管理者には一覧表で修正件数や種別の集計を報告する。この二段構えにすることで、現場の作業効率と管理の透明性を両立できます。
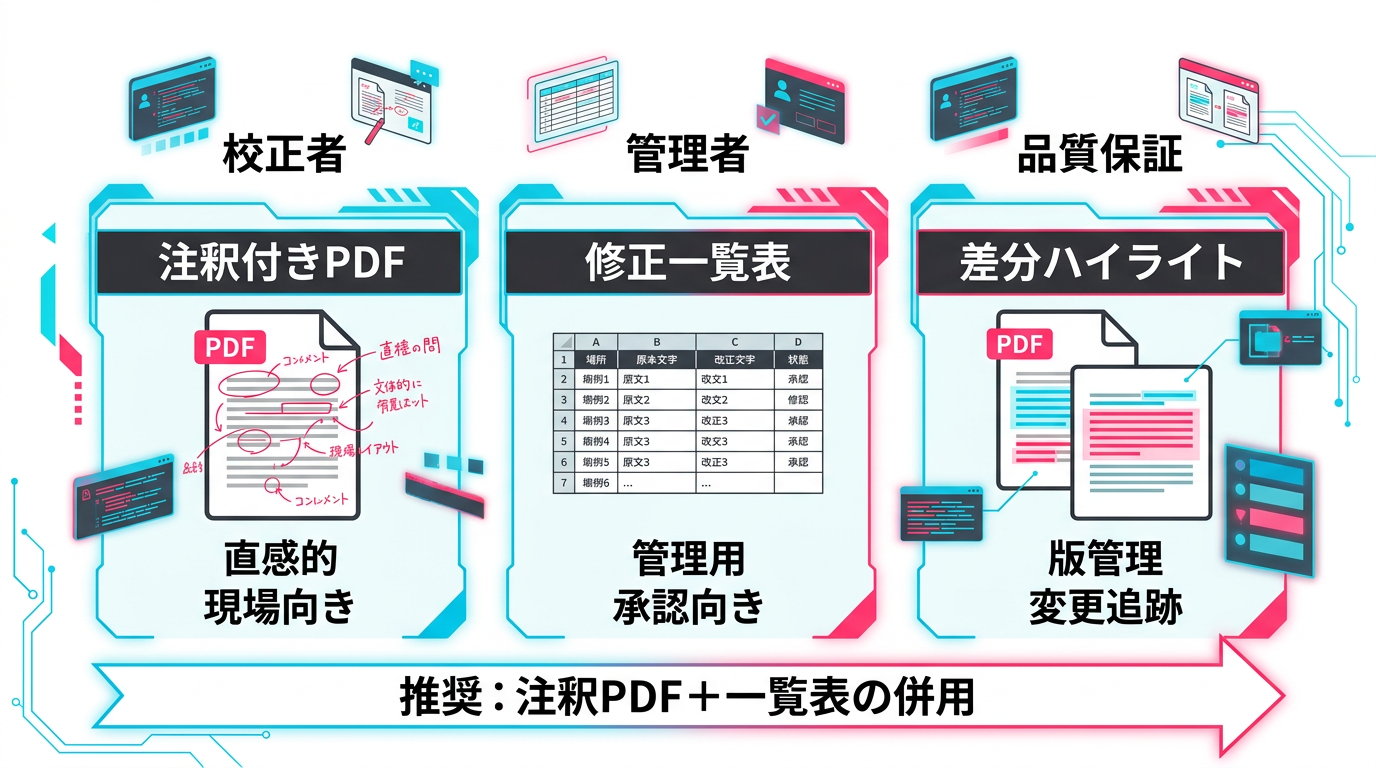
図3: 差分レポートの3つの形式と使い分け
Step 4: 修正反映 ― PDFに戻すまでの設計
差分レポートで修正箇所が明確になったら、最後のステップは修正の反映です。ここでPDF特有の制約が再び現れます。
PDFを直接編集してテキストを修正することは技術的には可能ですが、フォントの崩れや行間のずれが発生しやすく、品質の高い文書には不向きです。正しいアプローチは、原稿ファイル(Word、InDesign、PowerPointなど)に修正を反映し、PDFを再度書き出すことです。
このため、PDF校正のワークフロー全体を設計する際には「原稿ファイルがどこにあるか」を最初に確認してください。原稿ファイルが失われている場合は、PDFから最も近い再現が可能なファイル形式に変換してから修正する必要があります。
PDF種別で変わる最適アプローチ
PDF校正の精度とコストは、対象PDFの種別によって大きく変わります。自社で扱うPDFがどの種別に該当するかを把握した上で、最適なアプローチを選択してください。
ネイティブPDF(テキスト埋め込みあり)
WordやInDesignからPDFに変換した文書が該当します。テキスト情報がPDF内部に保持されているため、テキスト抽出の精度が高く、OCRは不要です。社内文書、契約書、報告書の多くがこのタイプです。
最適アプローチ: wordrabbitやTypolessにPDFを直接アップロードするか、テキスト抽出ツール(PyMuPDF等)で取り出してLLMに入力します。コストが低く、処理速度も速いため、大量の文書を一括校正する場合にも向いています。
スキャンPDF(紙→デジタル変換)
紙の文書をスキャナーで読み取ったPDFです。契約書の控え、過去の紙文書のデジタル化、FAXのPDF保存などが該当します。
最適アプローチ: OCR処理が必須です。Typolessは内蔵OCRエンジンで縦書きにも対応しています。LLMに直接投入する場合は、GeminiがスキャンPDFで94%の精度を達成しており、現時点では最も高い精度を出せます。スキャン時の解像度は300dpi以上を推奨します。
画像PDF・デザインPDF
広告のクリエイティブ、カタログ、ポスターなど、テキストがデザインの一部として画像化されているPDFです。印刷業界やマーケティング部門で頻出します。
最適アプローチ: マルチモーダルLLMの出番です。PDFを画像として認識し、デザイン内のテキストを読み取って校正できます。ChatGPTで文章校正する方法で紹介しているCanvas機能も、画像内テキストの校正に活用できます。ただし、デザイン要素とテキスト要素の区別が難しいケースがあるため、校正対象のテキスト範囲をプロンプトで明示することが重要です。
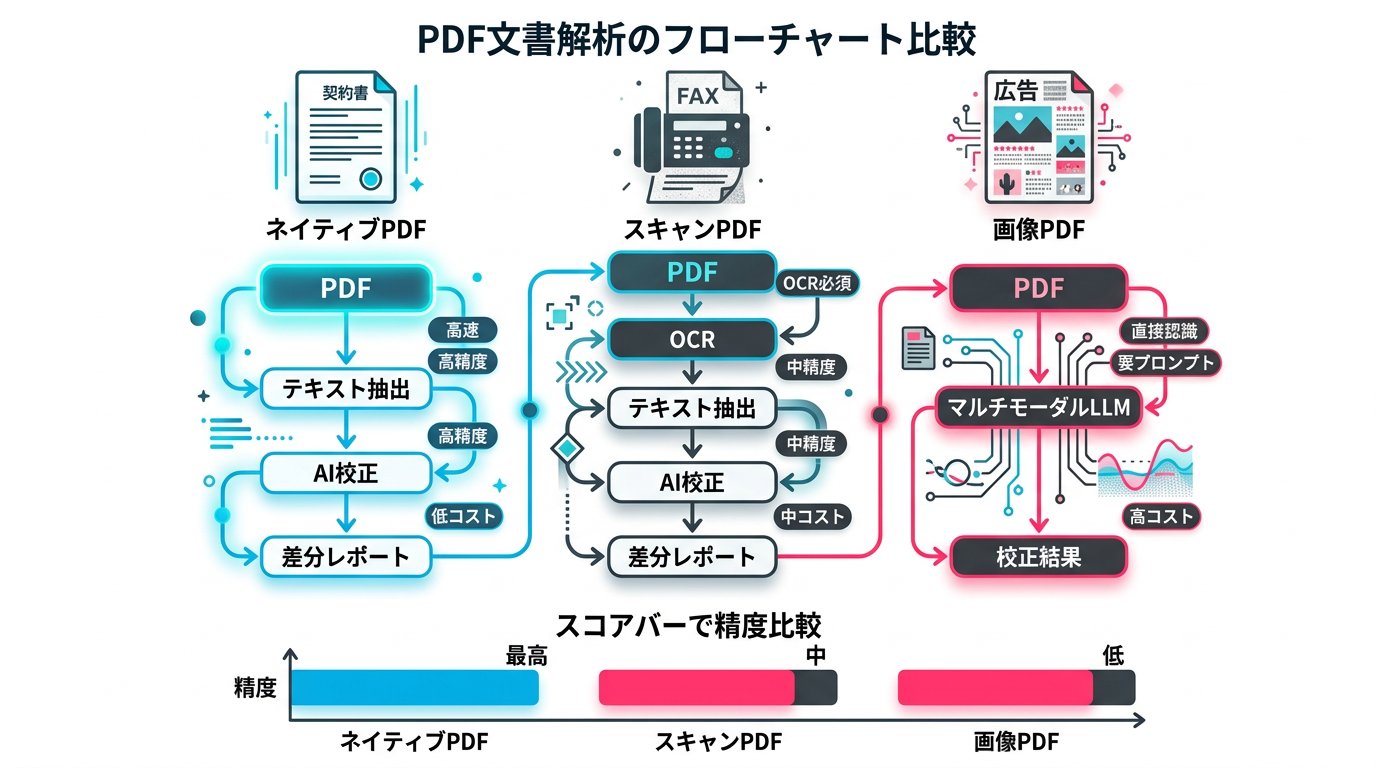
図4: PDF種別ごとの校正アプローチ比較
実務で使えるPDF AI校正ツールの選び方
PDF校正に対応したAI校正ツールを、選定基準と合わせて整理します。
日本語特化ツール
wordrabbit(レメディーズ社)は、日本語特化のAI校正ツールの中で最もPDF対応が進んでいます。PDFをアップロードするだけで、縦書き・段組み・ルビを含む複雑なレイアウトから98%の精度でテキストを抽出し、校正結果をPDFレイアウト上に表示できます。10万文字超の長文にも対応しており、講談社が社内の校正支援システム「ごじとる」にwordrabbitのAPIを採用した事例があります。PDF校正はBusiness Teamプラン以上で利用可能です。
Typoless(朝日新聞社)は、新聞校正40年のノウハウを持つ朝日新聞社が開発したツールです。2024年10月からPDF対応を開始し、OCRエンジンを全面的に再構築して縦書き認識の精度を大幅に向上させました。ISO/IEC 27001:2022を取得しており、入力ファイルをサーバーに保存しないセキュリティポリシーは、機密文書を扱う企業にとって重要な選定基準になります。PDF対応はPremium+Plusプラン(月額7,700円)から利用できます。
IWI日本語校正ツール(インテリジェントウェイブ社)は、BERT(言語モデルの一種)を活用した文脈ベースの校正が特徴です。PDF、Word、Excel、PowerPointに対応しており、文脈の自然さをAIが判断する独自のアプローチを採用しています。
LLMの直接活用
汎用LLMを使ったPDF校正は、専用ツールにはないカスタマイズ性が強みです。「この業界の専門用語リストに照らして表記を統一してください」「この契約書の条項間で矛盾がないか確認してください」といった、業務固有のチェックが可能です。
選定のポイントは、PDF校正の対象と頻度で判断することです。月に数回、特定の文書を校正する程度ならLLMの直接利用で十分です。日常的に大量のPDFを処理するなら、専用ツールのバッチ処理機能と辞書管理機能が活きてきます。AI校正ツールの選び方も参考にしてください。
まとめ
PDF校正のAI自動化は、「テキスト抽出」というPDF特有の工程をクリアできるかどうかが成否を分けます。
- 3層問題で課題を診断する: テキスト層(抽出精度)、構造層(レイアウト解釈)、意味層(内容チェック)のどこにボトルネックがあるかを特定する
- 4ステップパイプラインで設計する: テキスト抽出→AI校正→差分レポート→修正反映の流れを一気通貫で構築する
- PDF種別に応じたアプローチを選ぶ: ネイティブPDFは高速・高精度、スキャンPDFはOCR必須、画像PDFはマルチモーダルLLMが有効
- ツールは用途と頻度で選ぶ: 大量処理なら専用ツール(wordrabbit、Typoless)、業務固有のチェックならLLM直接利用
次のアクションとして、まず自社で校正が必要なPDF文書を10件程度集め、ネイティブPDF・スキャンPDF・画像PDFの比率を確認してください。その比率に応じて、最適なツールとパイプラインの組み合わせが見えてきます。
よくある質問(FAQ)
PDFをそのままAI校正ツールに入れられますか?
一部のツールは対応しています。wordrabbitやTypolessはPDFを直接アップロードしてAI校正できます。また、Claude・GPT・GeminiなどのLLMもPDFファイルを直接読み込んで校正指示を出せます。ただし、スキャンPDFや画像PDFではOCR精度がボトルネックになるため、事前にテスト文書で精度を確認してください。
スキャンPDFの校正精度はどのくらいですか?
OCR精度に依存しますが、2026年現在のマルチモーダルLLMはスキャンPDFでも90〜94%の精度を実現しています。特にGeminiはビジョン機能の統合により94%の精度を達成しています。ただし、手書き文字や低解像度のスキャンでは精度が大きく下がるため、300dpi以上でのスキャンを推奨します。
PDF校正と通常の文章校正は何が違いますか?
最大の違いは「テキスト抽出」の工程が必要な点です。WordやテキストファイルならそのままAIに入力できますが、PDFはフォーマットの性質上、まずテキストを正確に取り出す必要があります。段組み・表・ヘッダーなどのレイアウト情報が抽出時に失われるリスクもPDF特有の課題です。
PDF校正のAI化でどのくらい時間を削減できますか?
放射線科の読影レポートを対象にした研究では、AIによる校正は1件あたり16秒で完了し、人間の82〜121秒と比較して5〜7倍の高速化が報告されています。エラー検出感度もAIが0.89と人間の0.33〜0.69を上回りました。業務全体では、テキスト抽出を含めても従来の手作業比で60〜70%の時間削減が見込めます。

この記事の著者
Naosy 編集部
レビュー・校正・審査プロセスの最適化に関する実践的なナレッジを発信しています。



