RAG構築の実践ガイド ― 審査業務で成果を出す5ステップと失敗しない進め方
RAGを審査・チェック業務に導入するための実践ガイド。構築5ステップ、よくある3つの失敗パターン、PoC→本番化のロードマップ、2026年最新トレンドまで体系的に解説します。
「RAGが良いのは分かった。でも、実際にどこから手をつければいいのか分からない」 — RAG(検索拡張生成)の概念を理解した次のステップで、多くのチームが立ち止まります。
RAGで審査基準を常に最新に保つ仕組みでは、なぜRAGが審査業務に必要なのか、その技術的な仕組みを解説しました。本記事はその実践編です。「どう構築するか」「何から始めるか」「どこで失敗するか」を、ビジネス視点で整理します。
概念を理解することと、実際にシステムを動かすことの間には大きなギャップがあります。NTTデータの2025年レポートでは、RAG構築の「民主化」が進む一方で、PoCで止まってしまう企業が依然として多いと指摘されています。その原因の多くは、技術的な難易度ではなく、構築プロセスの全体像が見えていないことにあります。
この記事では、審査・チェック業務に特化したRAG構築の5ステップ、現場で繰り返される3つの失敗パターン、そしてPoCから本番環境へスケーリングするためのロードマップを示します。
なぜ審査業務にRAGが必要なのか
審査業務の現場では、担当者が法令やガイドラインを手作業で確認し、判断を下しています。この作業には2つの構造的な問題があります。
1つ目は基準の陳腐化です。薬機法、景表法、金商法など、審査に関わる法令は年間を通じて頻繁に改正されます。LLM(大規模言語モデル)を直接使うだけでは、学習時点の古い情報に基づいた回答が返ってくるリスクがあります。これは単なる不正確さではなく、法的リスクに直結する問題です。
2つ目は属人化です。「この法令の解釈はあの担当者に聞かないと分からない」という状態は、組織のリスクそのものです。担当者の異動や退職によって、審査品質が突然低下することがあります。
RAGはこの2つの問題を同時に解決します。審査に必要な法令やガイドラインを外部の知識ベースとして管理し、質問のたびに最新の情報を検索してからAIが回答を生成します。ファインチューニング(モデルの再学習)と異なり、文書を差し替えるだけで最新基準に追従でき、コストも大幅に抑えられます。
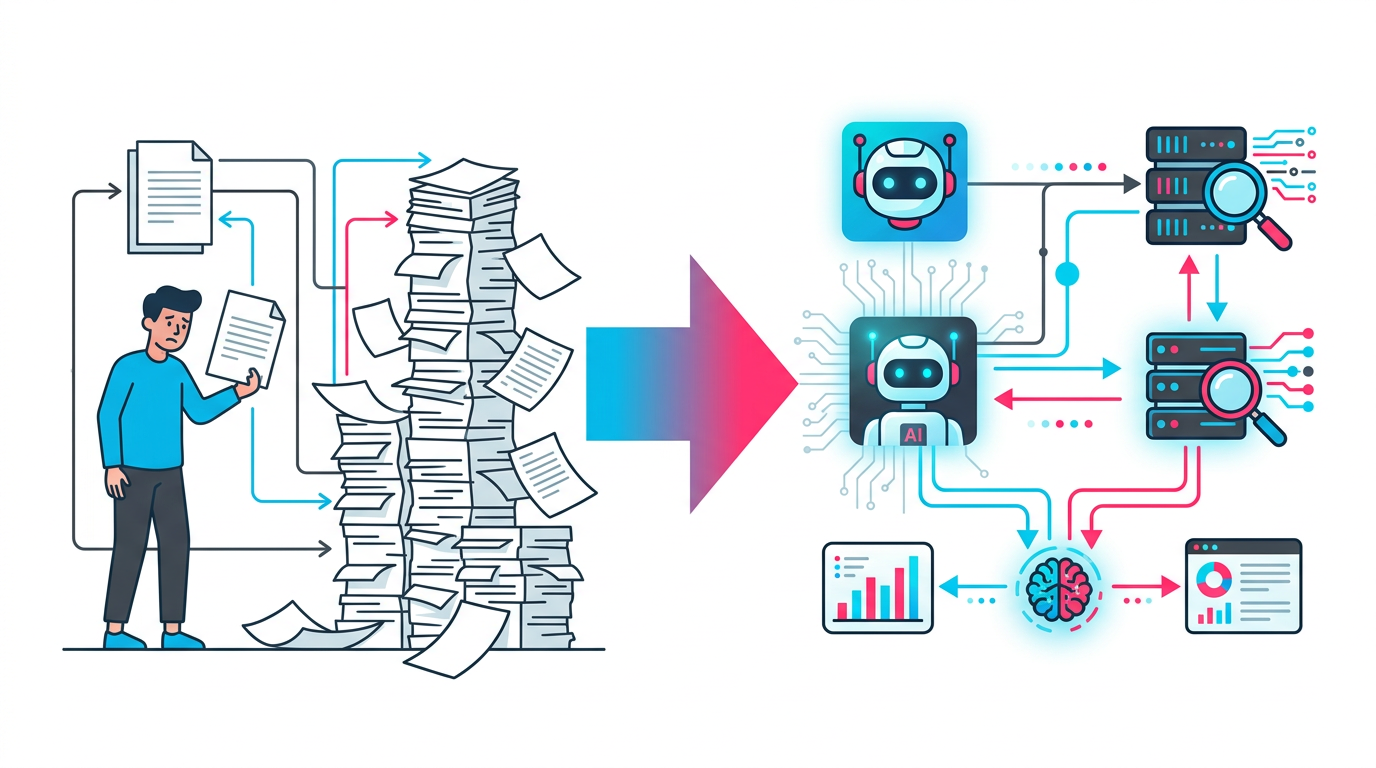
図1: 従来の審査プロセスからRAG活用への転換
RAG構築の全体像 — 5つのステップで理解する
RAGの構築は、大きく5つのステップに分かれます。各ステップで何をするのか、審査業務ではどこに注意すべきかを整理します。
ステップ1:対象文書の選定と前処理
最初のステップは、RAGに取り込む文書を決めることです。「社内のすべての文書を入れたい」という要望はよく聞きますが、これはPoCを失敗させる最大の原因になります。
まず1つの業務領域に絞ることを推奨します。たとえば「広告審査に関する景表法ガイドライン」や「社内の契約審査チェックリスト」など、範囲が明確で更新頻度を把握しやすい文書から始めてください。
前処理では、PDFやWordから構造を保ったままテキストを抽出します。表組みや箇条書き、章番号などの構造情報は、後のチャンク分割で精度を大きく左右するため、この段階で可能な限り保持することが重要です。
ステップ2:チャンク分割 — 精度を決める最重要設計
抽出したテキストを意味のある塊(チャンク)に分割します。このステップがRAGの精度を最も左右します。
単純な「500文字ずつ切る」固定長分割は、法律文書や審査基準には適しません。たとえば「第3条(適用範囲)」の例外規定が次のチャンクに分断されると、AIは例外条件を見落として不正確な回答を返します。
審査文書に適した分割アプローチは以下のとおりです。
- 構造ベース分割: 条文の番号、見出し、章立てを境界として使う。法令文書であれば「条」単位での分割が自然です
- 意味的分割: 文ごとの意味的な類似度を計算し、トピックが切り替わるポイントで分割する。前後の文脈を壊さずに済みます
- 親子チャンク: 小さなチャンク(300文字)で検索精度を上げつつ、LLMには親チャンク(1500文字)を渡して文脈を補う階層的なアプローチです
ソフトバンクの事例では、チャンク分割とデータ前処理の改善だけで、RAGの回答精度が75%向上したと報告されています。技術的な工夫よりも、まずデータの品質を高めることが優先です。
ステップ3:ベクトル化と検索基盤の構築
分割したチャンクをベクトル(数値の配列)に変換し、ベクトルデータベースに格納します。ユーザーの質問もベクトル化し、意味的に近いチャンクを高速で検索する仕組みを作ります。
ベクトルデータベースの選定は、組織の規模と運用体制で判断します。PoCや小規模導入であればオープンソースのChromaやQdrantが手軽です。既存のPostgreSQLを使っている組織であれば、pgvector拡張を追加するだけでベクトル検索を始められるため、新たなインフラを構築する必要がありません。
ステップ4:検索結果の精度向上(リランキング)
ベクトル検索の結果は、必ずしも質問に対して最適な順序で返ってくるとは限りません。リランキング(再順位付け)を導入することで、検索結果の中から真に関連性の高いチャンクだけをLLMに渡します。
RAGで審査基準を常に最新に保つ仕組みで詳しく解説していますが、ある法務データRAGの事例では、リランキング導入により応答時間が大幅に短縮され、LLMに渡すコンテキスト量も大幅に圧縮されたと報告されています。審査業務では「必要な条文だけを正確にLLMに渡す」ことが品質に直結するため、リランキングは必須の工程です。
ステップ5:生成と検証 — 根拠付き回答の仕組み
最後のステップでは、検索されたチャンクをコンテキストとしてLLMに渡し、回答を生成します。審査業務で最も重要なのは、この回答がどの文書のどの部分に基づいているかを明示する仕組み(グラウンディング)です。
「この広告表現は景表法第5条に基づき問題がある可能性があります」という回答と、根拠が不明なまま「問題がある可能性があります」という回答では、審査担当者が受ける信頼感がまったく異なります。引用元の文書名、条文番号、該当箇所を回答に付与する設計は、審査業務のRAGでは省略できません。
審査業務で陥りやすい3つの失敗パターン
RAG導入プロジェクトの現場で繰り返し見られる失敗パターンを整理します。事前に知っておくことで、同じ轍を踏まずに済みます。
失敗パターン1:「とりあえず全文書を入れる」データ品質問題
「社内文書を全部入れればAIが賢くなるはず」という発想は、RAGでは逆効果です。古いバージョンのガイドライン、重複した議事録、フォーマットの異なるPDFが混在すると、検索結果にノイズが混ざり、回答の信頼性が大幅に低下します。
AWSの事例レポートでは、あるRAGプロジェクトがベクトル検索自体をやめて別のアプローチに切り替えた経緯が紹介されています。原因を掘り下げると、データの前処理が不十分なまま大量の文書を投入したことが根本原因でした。
対策: まず対象文書を1つの業務領域に絞り、最新バージョンだけを取り込みます。文書にメタデータ(作成日、バージョン、適用範囲)を付与し、古い情報を検索結果から除外できる仕組みを最初から設計してください。
失敗パターン2:「固定長で切れば十分」チャンキング不良
500トークンや1000文字といった固定長でテキストを機械的に分割するアプローチは、審査文書では深刻な問題を引き起こします。法律の条文では「ただし、以下の場合を除く」という例外規定が本体と異なるチャンクに分断され、AIが例外条件を無視した回答を返すことがあります。
プロンプトエンジニアリングで審査基準を正確に伝える技術で解説しているように、AIに渡す情報の質がそのまま回答の質を決めます。チャンク分割の失敗は、いくらプロンプトを工夫しても取り返せません。
対策: 文書の構造(見出し、条文番号、箇条書き)を活かした構造ベース分割を採用します。さらに、分割後のチャンクを実際に検索してみて、必要な情報が正しく返ってくるかを手動で確認するテストを必ず実施してください。
失敗パターン3:「動いたら完成」評価体制の欠如
PoCで「それらしい回答が返ってきた」ことを成功と見なし、定量的な評価を行わないまま本番投入するケースがあります。しかし、RAGの回答品質は取り込む文書が増えるほど変動しやすく、定期的な評価なしには品質を維持できません。
AI審査の品質をどう測るかで紹介した評価指標の考え方は、RAGにもそのまま適用できます。RAG固有の評価フレームワークとしては、TruLensが提唱する「RAG Triad」が広く採用されています。
- Context Relevance: 検索されたチャンクが質問に関連しているか(検索の質)
- Faithfulness: AIの回答が検索されたチャンクの内容だけに基づいているか(生成の質)
- Answer Relevance: 最終回答が元の質問に的確に答えているか(全体の質)
DeNAの社内AIヘルプデスクでは、この評価を自動化するパイプラインを構築し、継続的に精度をモニタリングしています。手動で回答を確認するのではなく、評価を仕組み化することが本番運用の鍵です。
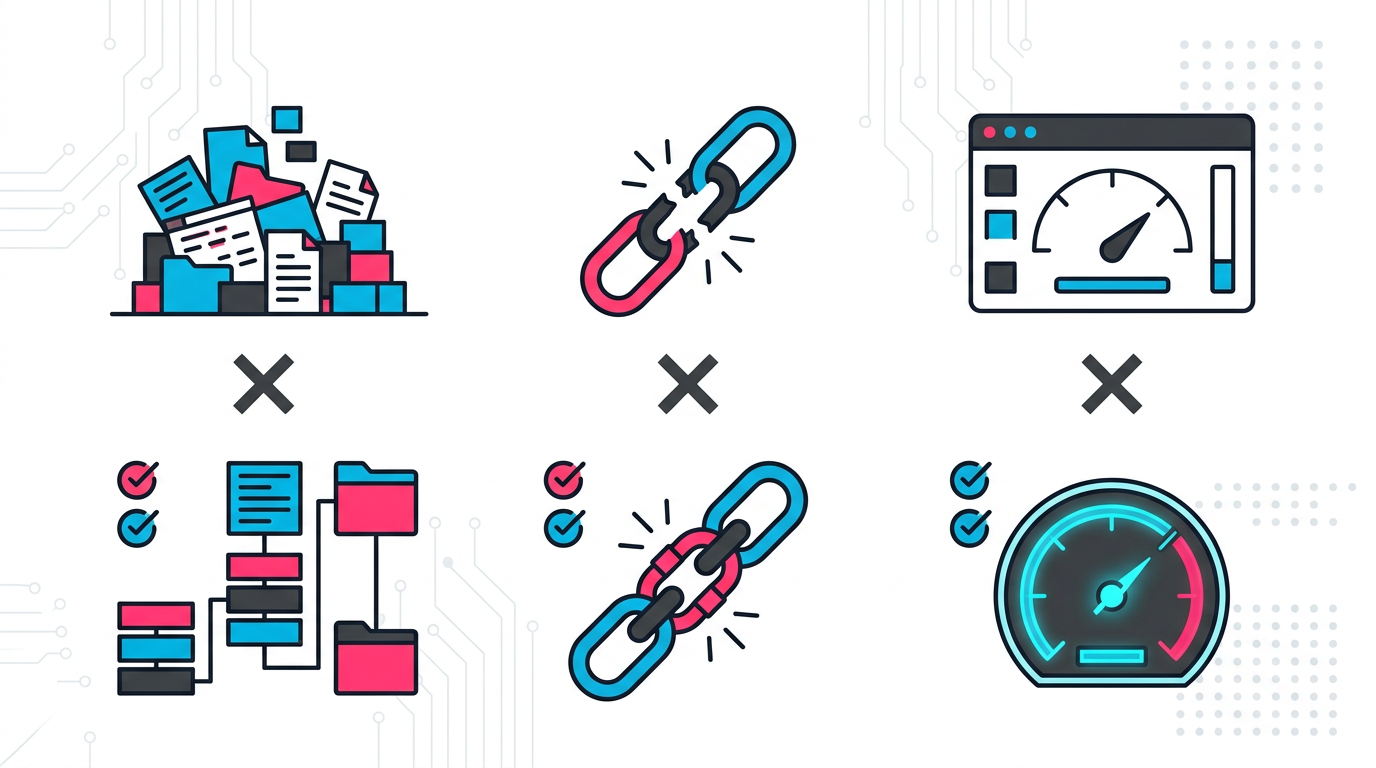
図3: 審査業務RAGの3大失敗パターン
PoCから本番環境へ — スケーリングの実践ロードマップ
RAGの構築は「動くものを作る」ことよりも「本番で安定して運用する」ことのほうが難しいとよく言われます。PoCから本番環境への移行を3つのフェーズに分けて進める方法を紹介します。
フェーズ1:検証(2〜4週間)
最初のフェーズでは、1つの業務文書でRAGの有効性を検証します。
たとえば50人規模の品質管理部門で、広告審査ガイドラインをRAGに取り込むシナリオを考えてみてください。対象文書は景表法に関する社内ガイドライン1冊(約50ページ)。この文書を構造ベースで分割し、ベクトル化して簡易的なチャットインターフェースで審査担当者に使ってもらいます。
この段階で確認すべきことは3つです。「検索結果が正しいか」「回答に根拠が付いているか」「担当者が業務で使えると感じるか」。技術的な完成度よりも、業務上の価値があるかどうかの検証に集中します。
フェーズ2:拡張(1〜2ヶ月)
PoCで有効性が確認できたら、対象文書の範囲を広げます。関連する法令(たとえば薬機法や特商法のガイドライン)を追加し、複数の法域にまたがる審査に対応できるようにします。
このフェーズでは、文書が増えることで検索精度が下がる問題に対処します。リランキングの導入、メタデータによるフィルタリング(「薬機法に関する質問では薬機法関連の文書のみを検索対象にする」など)、そして評価パイプラインの自動化がポイントです。
また、法令が改正されたときに知識ベースを更新する運用フローもこのフェーズで確立します。全文書を再処理するのではなく、変更があった文書だけを更新するインクリメンタル・インデクシングの仕組みを構築することで、更新のコストと時間を大幅に削減できます。
フェーズ3:定着(継続的)
本番環境で安定運用を始めた後も、RAGの品質は放置すると劣化します。新しい文書が追加されるたびに検索結果のバランスが変わり、以前は正確だった回答が不正確になることがあります。
定着フェーズでは、評価指標の定期モニタリング、ユーザーからのフィードバック収集、そして文書更新時の自動同期を回し続けます。AIテキストチェック自動化の始め方で紹介したように、チェック業務の自動化は「導入して終わり」ではなく、継続的な改善サイクルが不可欠です。
| フェーズ | 期間 | 対象範囲 | 重点タスク |
|---|---|---|---|
| 検証 | 2〜4週間 | 1つの業務文書 | 業務価値の確認、構造ベース分割の検証 |
| 拡張 | 1〜2ヶ月 | 複数の法令・ガイドライン | リランキング導入、評価自動化、更新フロー構築 |
| 定着 | 継続的 | 全審査業務 | 品質モニタリング、フィードバック反映、自動同期 |
2026年のRAG最新トレンド — Agentic RAGとGraphRAG
RAGの技術は急速に進化しています。2026年現在、注目すべき2つのトレンドを紹介します。
Agentic RAG:自律的に検索を繰り返すAI
従来のRAGは「1回検索して、1回回答する」シンプルなパイプラインでした。Agentic RAGは、AIエージェントが「考える → 検索する → 結果を確認する → 必要なら再検索する」というサイクルを自律的に繰り返します。
たとえばAIエージェントは審査業務をどう変えるかで紹介したように、AIエージェントの自律的な判断能力とRAGの検索能力を組み合わせることで、複数の法令を横断した複雑な審査にも対応できるようになります。「この広告表現は景表法と薬機法の両方に抵触する可能性があるか?」といった複合的な質問に対して、AIが複数の法令を自動的に検索し、総合的な判断を返す仕組みです。
ソフトバンクの技術ブログでは、Agentic RAGが従来のRAGの「1回の検索で必要な情報が見つからない」という根本的な課題を解決すると解説しています。
GraphRAG:文書間の関係性を理解するRAG
通常のRAGは個々のチャンクを独立して検索しますが、GraphRAGは文書間の関係性をグラフ構造として保持します。「第3条は第5条の例外規定である」「このガイドラインは2024年の法改正を受けて改訂された」といった情報のつながりを検索に活用できます。
審査業務では、1つの条文だけでなく、関連する判例、通達、ガイドラインの解釈を横断的に参照する必要があります。GraphRAGは、こうした複雑な参照関係を持つ文書群に対して、従来のベクトル検索よりも的確な回答を生成できる可能性を持っています。
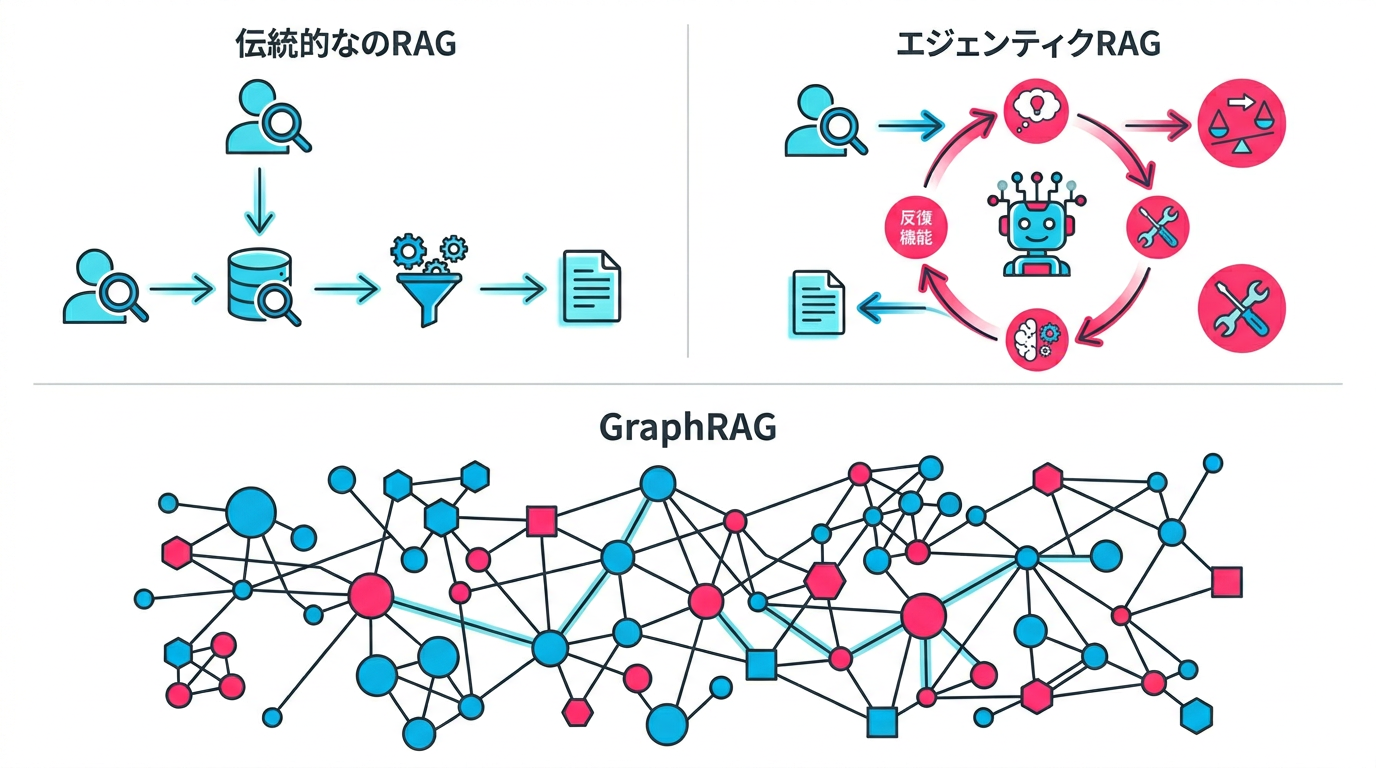
図4: RAGの進化 — 従来型からAgentic RAG・GraphRAGへ
よくある質問(FAQ)
RAG構築にはどのくらいの期間がかかりますか?
PoCであれば2〜4週間で構築可能です。本番環境への移行には追加で1〜2ヶ月を見込みます。対象文書の範囲や組織の承認プロセスによって期間は変動しますが、1つの業務文書に絞れば短期間で成果を出せます。
RAGとファインチューニングはどちらを選ぶべきですか?
審査業務のように基準が頻繁に更新される場合はRAGが適しています。ファインチューニングは法改正のたびにモデル全体の再学習が必要でコストが高く、どの法令バージョンに基づく回答かも区別できません。RAGなら検索対象の文書を差し替えるだけで最新基準に追従できます。両者の違いについては、ファインチューニングとプロンプト設計の使い分けも参考にしてください。
小規模なチームでもRAGを導入できますか?
可能です。マネージドサービスを活用すれば、インフラ運用の負担を大幅に減らせます。まず1つの業務文書(例:社内審査ガイドライン)をパイロット対象にして、小さく始めることを推奨します。
RAGの精度はどう測ればよいですか?
Faithfulness(忠実性)、Context Relevance(検索の関連性)、Answer Relevance(回答の的確さ)の3指標で評価するRAG Triadフレームワークが標準的です。自動評価パイプラインを構築し、定期的にスコアを計測する運用が推奨されます。LLMの誤情報生成を防ぐ審査設計で紹介した品質管理の考え方も、RAG評価の設計に応用できます。
まとめ
RAG構築は、技術的な難易度よりも「正しい順序で、正しい範囲から始める」ことが成否を分けます。本記事で解説したポイントを整理します。
- 5ステップの全体像: 文書選定→チャンク分割→ベクトル化→リランキング→根拠付き生成。各ステップで審査業務特有の設計判断が求められます
- 3つの失敗パターン: データ品質の軽視、固定長チャンキング、評価体制の欠如。事前に知っておくだけで回避できる落とし穴です
- PoCから本番へのロードマップ: 検証→拡張→定着の3フェーズ。1つの業務文書から小さく始め、段階的に対象を広げていくアプローチが成功率を高めます
- 最新トレンド: Agentic RAGとGraphRAGが、複数法令の横断検索や文書間の関係性理解を可能にし、審査業務のRAGをさらに高度化する方向に進化しています
最初の一歩として推奨するのは、最も更新頻度が高く、かつ業務インパクトの大きい文書を1つ選んでPoCを始めることです。全文書を一度に取り込むのではなく、小さく始めて検証し、成功体験を積み重ねながら拡張していく進め方が、RAG構築を成功させる最も確実な道筋です。

この記事の著者
Naosy 編集部
レビュー・校正・審査プロセスの最適化に関する実践的なナレッジを発信しています。



