審査基準をAIに教える ― ルールベース×LLMハイブリッド設計の実践ガイド
正規表現やキーワードマッチで判定すべき項目と、LLMの柔軟な判断に任せるべき項目の切り分け方を解説。直列・並列・カスケードの3パターンで、審査AIの精度とコストを最適化する実装手法を紹介します。
「全部AIに任せれば楽になる」――この発想で審査AIを導入した企業のほぼすべてが、3ヶ月以内にコストか品質の問題にぶつかります。 私たちが支援してきた審査AI導入プロジェクトで学んだのは、「何をルールで判定し、何をLLMに任せるか」の設計こそが成否を分けるということです。
「電話番号が含まれていないか」のチェックに、わざわざLLMのAPIを呼ぶ必要はありません。正規表現なら1ミリ秒以下で確実に判定できます。逆に、「この表現が消費者に誤解を与えないか」という判断を正規表現だけで実現するのは不可能です。審査項目ごとに最適な判定手段を選ぶ――このハイブリッド設計が、審査AIの精度・コスト・速度を同時に最適化する鍵です。
この記事では、ルールベースとLLMを組み合わせたハイブリッド審査システムの設計手法を、3つのアーキテクチャパターンと実装ステップで解説します。
「全部LLMに任せる」が危険な3つの理由
LLMの能力が飛躍的に向上した2025年以降、「チェック項目をすべてLLMに処理させればいい」という発想が広がっています。しかし実務でこのアプローチを取ると、3つの問題が発生します。
理由1: 判定が確率的になる
LLMは確率モデルです。同じテキストを同じプロンプトで処理しても、実行するたびに異なる結果を返す可能性があります。「この広告文に薬機法違反の表現が含まれるか」という質問に対して、ある日は「違反なし」、別の日は「違反の可能性あり」と判定が揺れることがあります。
審査業務で判定が揺れるのは致命的です。同じ文書を2回チェックして結果が変わるシステムでは、審査者は「どちらが正しいのか」を判断できず、結局すべてを手作業で確認し直すことになります。対して、正規表現やキーワードリストによる判定は完全に決定的(同じ入力に対して常に同じ結果)です。
理由2: コストが爆発する
LLMのAPI呼び出しにはトークン単位の課金が発生します。審査対象のテキストが長いほど、チェック項目が多いほど、コストは膨らみます。月間1万件の広告文を10項目でチェックする場合、すべてをLLMに処理させると月額のAPI費用は数十万円に達することもあります。
一方、ルールベースのチェックは自社サーバーで実行すれば追加コストはほぼゼロです。禁止ワードのマッチング、電話番号や個人情報のパターン検出、必須表記の有無確認など、ルールで処理できる項目をルールに任せるだけで、API費用を50〜70%削減できます。
理由3: 応答速度が遅くなる
LLMの推論には数秒のレイテンシ(応答遅延)が発生します。1件のチェックに3秒かかるとして、1万件を処理すると約8時間。チェック項目が10個あれば、単純計算で80時間です。実際にはバッチ処理や並列化で短縮できますが、ルールベースなら同じ処理を数分で完了します。
文章チェックの自動化でも触れていますが、チェック項目の設計段階で「何を自動化するか」を整理することが重要です。その整理の軸として、「ルールで十分な項目」と「LLMが必要な項目」の区分が有効です。
ルールベースは「旧式」ではない
LLMの登場で「ルールベースは時代遅れ」と思われがちですが、それは誤解です。ルールベースは「確実に判定できる項目」に対しては、速度・コスト・確実性のすべてでLLMを上回ります。最適なのは「適材適所」の設計です。
ルールベースが得意な審査項目 ― 判定基準が「書き下せる」もの
ルールベースの判定に向いている審査項目には、共通する3つの特徴があります。
特徴1: 判断基準が明文化できる
「○○という表現が含まれていたらNG」「○○の数値が○以上ならNG」のように、判断基準をif文で書き下せる項目です。薬機法チェックで扱っている「治る」「効く」「万能」などの禁止表現リストは、キーワードマッチングで高精度に検出できます。
特徴2: 二値判定で完結する
「含まれている or 含まれていない」「基準値以上 or 未満」のように、判定結果がYes/Noで完結する項目です。グレーゾーンの判断が不要なため、ルールベースの確定的な判定が最も適しています。
特徴3: 文脈に依存しない
テキストの前後関係や全体の意味を読み解かなくても判定できる項目です。電話番号のパターン検出、URLの形式チェック、必須の免責事項が含まれているかの確認などが該当します。
具体的にルールベースが得意な審査項目を挙げます。
- 禁止表現の検出: 薬機法・景表法のNG表現リスト(「絶対に治る」「No.1」「最安値保証」など)とのマッチング
- 個人情報の検出: 電話番号、メールアドレス、マイナンバーなどの正規表現パターン
- 必須表記の確認: 特定商取引法に基づく表示、免責事項、著作権表記の有無
- フォーマットチェック: 文字数制限、禁止文字(全角英数や機種依存文字)、ファイル形式
- 数値の範囲チェック: 価格の上限・下限、割引率の妥当性、日付の整合性
広告審査AIの活用ガイドで紹介しているNG表現リストの多くは、このルールベースのチェックで高い検出率を実現できます。
LLMが得意な審査項目 ― 「文脈を読む」必要があるもの
LLMに判定を任せるべき項目にも、共通する3つの特徴があります。
特徴1: 文脈によって判定が変わる
同じ表現でも、前後の文脈によってOK/NGが変わる項目です。たとえば「効果があります」という表現は、科学論文の文脈では事実の記述ですが、健康食品の広告では薬機法違反になりえます。ルールベースでは「効果があります」を一律NGにするか一律OKにするかしかできませんが、LLMは文脈を読んで判断できます。
特徴2: 判断基準が「暗黙知」に依存する
「消費者に誤解を与えないか」「品位のある表現か」「ブランドイメージに合っているか」のように、判断基準を明確なルールに落とし込めない項目です。経験豊富な審査者の暗黙知をLLMのプロンプトに反映させることで、ある程度の再現が可能です。プロンプトエンジニアリングで審査基準を定義するの手法が、ここで活きてきます。
特徴3: 新しいパターンに対応する必要がある
ルールベースは既知のパターンしか検出できません。新しい表現や巧妙な言い回しで規制を回避しようとするケースに対しては、言語の意味を理解できるLLMが有効です。「治る」がNGなら「治った気がする」「回復を実感」と表現を変えてくる広告に対して、LLMは意味的な類似性を検出できます。
具体的にLLMが得意な審査項目を挙げます。
- 文脈依存の表現チェック: 文脈によってOK/NGが変わる表現の判定
- トーン・スタイルの評価: ブランドガイドラインに沿った文体かの判断
- 暗示的な規約違反の検出: 直接的な禁止表現を使わずに規制を回避する巧妙な表現
- 要約・整合性チェック: 見出しと本文の内容の一貫性、矛盾の検出
- 多言語の意味チェック: 翻訳文の意味的な正確性の確認(ルールベースでは不可能)
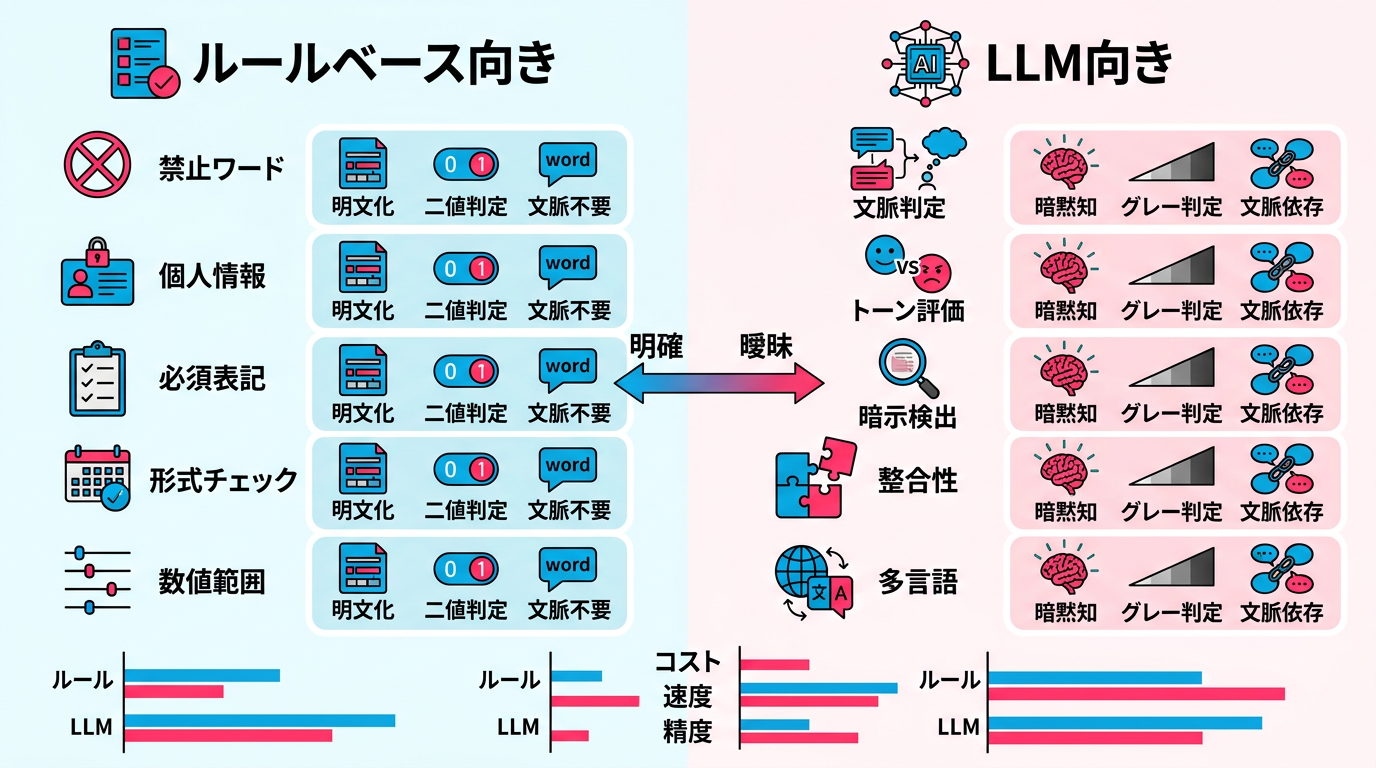 図2: ルールベース vs LLM ― 審査項目の振り分け基準
図2: ルールベース vs LLM ― 審査項目の振り分け基準
ハイブリッド設計の3パターン ― 直列・並列・カスケード
ルールベースとLLMの役割が整理できたら、次は両者をどう組み合わせるかの設計です。私たちが実務で使っている3つのアーキテクチャパターンを紹介します。
パターン1: 直列型 ― ルール→LLMの順に処理する
最もシンプルで導入しやすいパターンです。まずルールベースのチェックを実行し、ルールで確定判定できた項目は結果を確定します。ルールで判定できなかった項目だけをLLMに渡します。
直列型の最大の利点はコスト削減です。ルールベースで全体の60〜70%の項目が確定判定できれば、LLM APIの呼び出し回数は30〜40%に減ります。私たちの経験では、広告審査の場合、禁止表現チェック・個人情報チェック・必須表記チェックだけで全チェック項目の約60%をカバーできます。
直列型の注意点は、ルールベースの判定漏れがそのままLLMに渡されない(=チェックされない)リスクです。ルールの網羅性を定期的に検証する仕組みが必要です。
パターン2: 並列型 ― ルールとLLMを同時に実行する
ルールベースとLLMの両方で同じテキストを同時にチェックし、結果をマージ(統合)するパターンです。
並列型の利点は検出率の最大化です。ルールベースが見逃したパターンをLLMが拾い、LLMが判定を誤った項目をルールベースが正しく判定する。両者の強みが補完し合うことで、単独では達成できない高い検出率を実現できます。
デメリットはコストが高いことです。全件をLLMにも処理させるため、直列型のようなコスト削減効果はありません。また、ルールとLLMの判定が矛盾した場合の解決ロジック(どちらを優先するか)の設計が必要です。一般的には「NGが優先」(どちらかがNGならNG)の方針が安全です。
並列型は、コンプライアンスリスクが高く見逃しが許されない業務(金融商品の広告審査、医薬品の効能表示チェックなど)に適しています。
パターン3: カスケード型 ― 段階的に高精度なモデルへエスカレーション
処理コストの異なる複数のモデルを段階的に使い分けるパターンです。最初にルールベースで処理し、判定できない項目は軽量なLLM(HaikuやFlashなど)で処理し、それでも確信度が低い項目だけ高精度なLLM(OpusやProなど)に渡します。
カスケード型の利点はコストと精度のバランス最適化です。全件を高精度モデルで処理するコストの10〜20%で、同等の精度を達成できるケースもあります。
カスケード型の設計で重要なのは、各段階の「エスカレーション基準」です。確信度スコアが何%以下なら次の段階に渡すのか、この閾値(しきい値)の設定が全体の性能を左右します。閾値を低くすると次の段階に渡される件数が増えてコストが上がり、高くすると見逃しが増えます。
ファインチューニング vs プロンプト設計で解説しているように、使用するモデルの選択はコストと精度のトレードオフです。カスケード型はこのトレードオフを動的に最適化する設計と言えます。
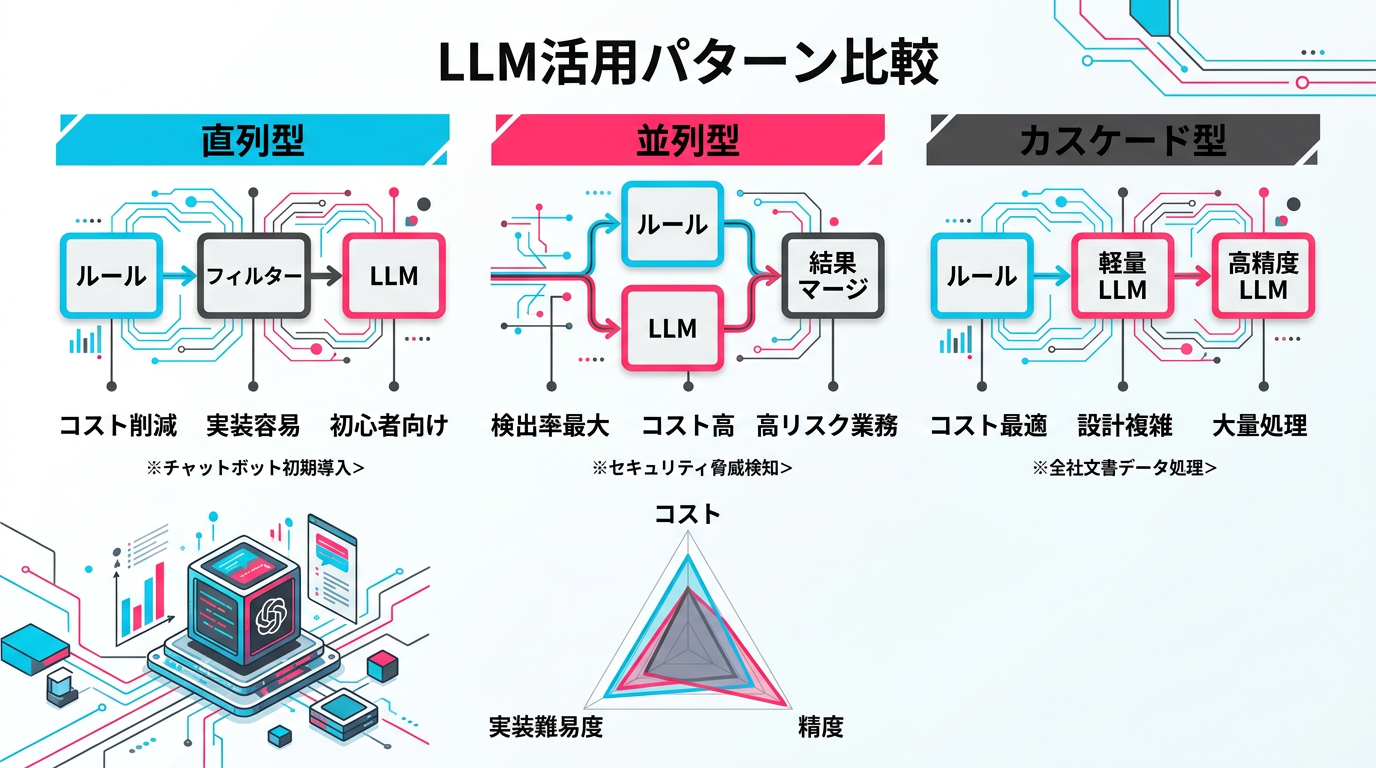 図3: 直列・並列・カスケード ― 3パターンの特性比較
図3: 直列・並列・カスケード ― 3パターンの特性比較
実装ステップ ― 既存ルールの棚卸しから始める
ハイブリッド設計を実装するステップを、直列型パターンを例に解説します。
ステップ1: 既存の審査基準を棚卸しする
まず、現在の審査で使っているチェック項目をすべて書き出します。多くの組織では、審査基準が「審査マニュアル」「過去の判定事例」「ベテラン審査者の暗黙知」に分散しています。これらを1つのスプレッドシートに集約し、すべてのチェック項目を一覧化します。
棚卸しの際に、各チェック項目に以下の3つのラベルを付けます。
- ルール可能: 正規表現やキーワードリストで判定できる(例: 「電話番号を含まないこと」)
- LLM推奨: 文脈理解が必要で、ルール化が困難(例: 「消費者に誤解を与えないこと」)
- 判断保留: どちらか分からない(PoC段階で検証する)
この棚卸しは、IT部門だけで行わないでください。実際に審査業務を行っている現場の担当者と一緒に作業することが必須です。ベテラン審査者が「当たり前すぎて言語化していない」チェック基準が、棚卸しで初めて明文化されるケースが多々あります。
ステップ2: ルールを実装する
「ルール可能」とラベル付けした項目から、ルールの実装を開始します。実装の優先順位は以下の基準で決めます。
- 出現頻度が高い項目: 全件に対して実行されるチェック(禁止表現リスト、個人情報検出など)を先に実装すると、LLMへの流入量が最も減る
- 判定が確実な項目: 誤検知が少ない項目(正規表現パターンでの電話番号検出など)を先に実装すると、信頼性が高い
- ビジネスインパクトが大きい項目: 見逃した場合の損失が大きい項目(法令違反に関わるチェックなど)を先に実装すると、リスクを早期に軽減できる
ルールは、非エンジニアでも追加・修正できる管理画面を設けることを推奨します。禁止表現リストの更新は法改正のたびに発生するため、エンジニアに依頼しなくても審査チームが自分で更新できる仕組みが運用効率を大きく左右します。
ステップ3: LLMプロンプトを設計する
「LLM推奨」の項目に対して、プロンプトを設計します。プロンプトエンジニアリングで審査基準を定義するの手法を活用し、チェック基準をプロンプトに構造化して埋め込みます。
プロンプト設計のポイントは、ルールベースで確定した情報をコンテキストとしてLLMに渡すことです。「このテキストにはルールベースで検出された禁止表現はありません。以下の観点でチェックしてください」と前提条件を伝えることで、LLMは重複チェックを避け、自身が得意な判定に集中できます。
また、LLMの出力には必ず確信度を付けさせます。「高確信(90%以上)」「中確信(70〜90%)」「低確信(70%未満)」のラベルを判定ごとに出力させ、低確信の判定は人間の審査者にエスカレーションします。
ステップ4: パイプラインを統合する
ルールベース→LLMの直列パイプラインを構築し、結果を統合して1つの審査レポートとして出力します。RAGで審査基準を最新に保つの仕組みを組み込む場合は、LLM呼び出しの前に関連する審査基準の検索と取得を挟みます。
統合の際に注意すべきは、すべてのチェック結果に「判定元」(ルール or LLM)を記録しておくことです。後から精度を分析する際に、どちらの判定が正確だったかを検証できます。この記録は、ルールとLLMの境界線を見直す際の重要なデータになります。
ルール↔LLMの境界線を定期的に見直す仕組み
ハイブリッド設計は「一度設計したら終わり」ではありません。ルールとLLMの境界線は、定期的に見直す必要があります。
見直しが必要になる3つの契機
契機1: LLMの判定精度が安定した項目をルール化する
LLMで処理している項目の中に、判定パターンが固定化しているものが見つかることがあります。たとえば「この表現パターンはLLMが常にNGと判定している」と分かれば、そのパターンをルール(正規表現やキーワードリスト)に変換してルールベースに移行できます。これにより、APIコストを削減しつつ判定速度を向上させます。
契機2: 新しい規制や基準が追加された
法改正や社内ルールの変更で新しいチェック項目が追加された場合、その項目が「ルール可能」か「LLM推奨」かを判定し、適切な側に配置します。
契機3: 誤判定が集中している項目を再分類する
ルールベースで誤検知(問題ないのにNGと判定)が多発している項目は、文脈理解が必要な項目である可能性があります。逆に、LLMで見逃し(問題があるのにOKと判定)が多い項目は、ルールベースの方が確実に検出できるかもしれません。
見直しの運用フロー
月次で以下のレビューを実施します。
- 誤判定の集計: ルール起因の誤検知とLLM起因の見逃しを集計し、項目別に分析する
- 境界線の調整提案: 誤判定が集中している項目について、ルール↔LLMの移行を提案する
- ルールの追加・更新: LLMの判定パターンから新しいルールを抽出し、ルールベースに追加する
- コストレビュー: LLMのAPI利用量とコストを確認し、ルール化で削減できる項目がないか検討する
この月次レビューの結果を蓄積することで、ハイブリッド設計は時間とともに精度が向上し、コストが最適化されていきます。
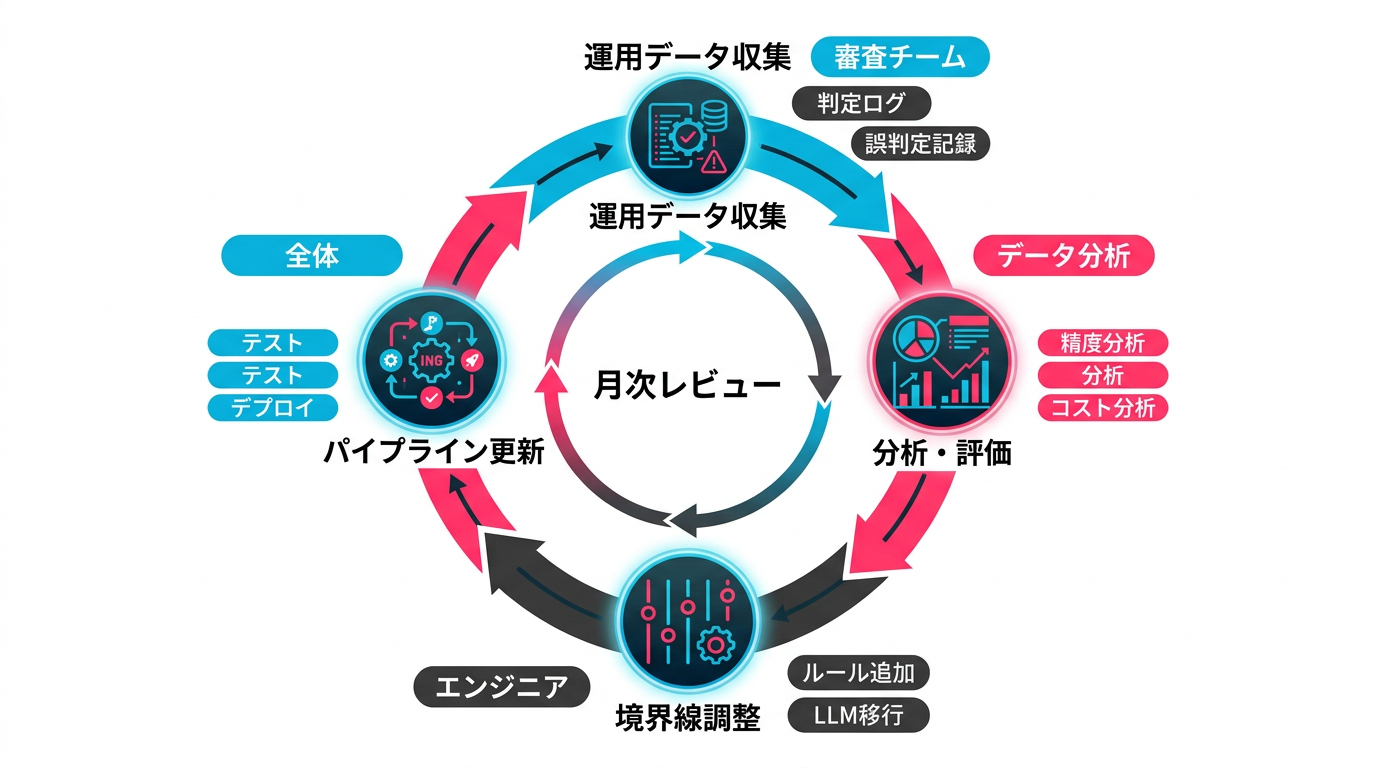 図4: 境界線の継続的見直しサイクル
図4: 境界線の継続的見直しサイクル
まとめ
審査AIの設計は「全部LLMに任せる」でも「全部ルールで処理する」でもなく、両者の強みを組み合わせたハイブリッド設計が最適解です。
- ルールベースは「確実に判定できる項目」に使う: 禁止表現マッチング、個人情報検出、フォーマットチェックなど、判定基準が明文化でき、文脈に依存しない項目
- LLMは「文脈理解が必要な項目」に使う: トーン評価、暗示的な規約違反の検出、文脈依存の表現チェックなど、ルール化が困難な項目
- 直列型から始める: 初めてのハイブリッド設計は直列型(ルール→LLM)が最もシンプルかつ効果的。ルールベースで60〜70%の項目を確定判定し、残りだけLLMに渡す
- 境界線は月次で見直す: ルールとLLMの役割分担は固定ではない。運用データに基づいて、定期的にチェック項目の再分類とルールの追加を行う
次のアクションとして、自社の審査チェック項目を一覧化し、各項目に「ルール可能」「LLM推奨」「判断保留」のラベルを付ける棚卸し作業から始めてください。この棚卸し結果が、ハイブリッド設計の出発点になります。
よくある質問(FAQ)
ルールベースとLLMのハイブリッド設計とは何ですか?
正規表現やキーワードリストによる確定的なチェックと、LLMによる文脈を考慮した柔軟な判定を組み合わせた審査システムの設計手法です。ルールベースで判定できる項目はルールに任せ、文脈理解が必要な項目だけLLMに渡すことで、精度・速度・コストのバランスを最適化します。
なぜ全部LLMに任せてはいけないのですか?
LLMは確率的に出力を生成するため、同じ入力でも判定が変わることがあります。また全件をLLMに処理させるとAPIコストが膨れ上がり、応答速度も遅くなります。「電話番号を含むか」のような明確な基準はルールベースの方が速く・安く・確実に判定できます。
3つのパターン(直列・並列・カスケード)のどれを選ぶべきですか?
初めてハイブリッド設計を導入するなら直列パターンがおすすめです。ルールベースで確定判定できる項目を先に処理し、残りだけLLMに渡す構成で、実装がシンプルかつコスト削減効果が高いです。判定精度を最大化したい場合は並列パターン、大量処理でコスト最適化が重要ならカスケードパターンを検討してください。
ルールベースとLLMの境界線はどう決めますか?
判断基準が明文化できるか、二値判定(Yes/No)か、文脈によって判定が変わるかの3軸で分類します。「禁止ワードリストに含まれるか」はルール向き、「表現が誤解を招くか」はLLM向きです。まず既存ルールを棚卸しし、ルール化できるものから段階的に切り分けてください。

この記事の著者
Naosy 編集部
レビュー・校正・審査プロセスの最適化に関する実践的なナレッジを発信しています。



