AI審査の誤判定対応 ― エスカレーションフローの設計ガイド
AIは必ず間違えます。問題は間違えた後の対応設計です。誤判定の4パターン分類、信頼度スコアによる3層ルーティング、エスカレーションフロー設計、異議申立プロセス、フィードバックループの構築方法を、2026年のAI-over-AIパラダイムを踏まえて解説します。
AI審査システムを導入した企業から、必ず聞こえてくる声があります。
「AIが間違えた。やっぱりAIは使えない」
しかし、これは問いの立て方が間違っています。AIは必ず間違えます。人間の審査員も間違えます。問題は「間違えるかどうか」ではなく、間違えた後にどう対応するかの設計です。
2026年現在、Claude 4.6 OpusやGPT-5.4のような高性能LLMでも、コンテンツモデレーションの完全自動化は現実的ではありません。EU DSAの2025年上半期統計では、内部アピールの約30%が判定覆しとなっており、AIモデレーションの限界は制度的にも認識されています。
この記事では、誤判定を前提とした「誤判定対応システム」の設計方法を解説します。
誤判定は「あって当然」― 問題は設計不備
AI審査の誤判定には大きく2種類あります。
- False Positive(FP / 偽陽性): 正常なコンテンツを「違反」と誤って判定する
- False Negative(FN / 偽陰性): 違反コンテンツを「正常」と見逃す
どちらもゼロにすることは不可能です。FPを減らそうとすればFNが増え、FNを減らそうとすればFPが増える。これは統計モデルの本質的なトレードオフであり、LLMベースの審査でも変わりません。
重要なのは、この前提を受け入れたうえで、誤判定を検知し、修正し、再発を防止する仕組みを設計することです。
「AIの精度が100%になったら導入する」という姿勢は、永遠に導入できないことを意味します。人間の審査精度も100%ではありません。AIと人間のハイブリッド体制で全体の精度を最大化する設計が必要です。
誤判定の4パターンと原因分析
誤判定を効果的に対処するには、パターン別に原因を特定する必要があります。
パターン1: 過検知型FP(感度過剰)
正常なコンテンツをAIが違反と誤判定するケースです。合法的な商品広告を「制限商品」としてブロックしたり、医療情報の記事を「薬事法違反」と判定したりする例が典型です。
主な原因: モデルの感度設定が高すぎる、訓練データにおける違反事例の偏り、プロンプトの判定基準が厳しすぎる
パターン2: バイアス型FP(属性偏り)
特定の属性を持つコンテンツが不当に誤検知されるケースです。Stanford大学の2025年研究(10,000サンプル)では、非ネイティブ英語話者の文章をAI生成コンテンツと誤判定するFP率が20%を超えることが報告されています。
主な原因: 訓練データの人口統計的偏り、言語パターンの多様性不足
パターン3: 回避型FN(意図的すり抜け)
違反者がパラフレーズやリライトで検出を回避するケースです。たとえば、禁止ワードを類似表現に置き換えたり、文字の間にスペースを挿入したりする手法があります。
主な原因: ユーザーの意図的回避テクニック、ルールベース検知の限界
パターン4: 陳腐化型FN(モデルの老朽化)
新しい違反手法が登場し、既存モデルでは検知できなくなるケースです。2026年現在、ハイブリッドライティング(AI起草→人間編集)が標準化し、「AI生成か人間作成か」の境界が曖昧になっています。この編集された「つなぎ」部分が新たなFPホットスポットにもなります。
主な原因: 訓練データの古さ、モデル更新頻度の不足、データドリフト
| パターン | 種別 | 例 | 主な対策 |
|---|---|---|---|
| 過検知型 | FP | 合法広告を制限商品と判定 | 閾値調整、プロンプト緩和 |
| バイアス型 | FP | 非ネイティブ文章をAI生成と誤判定 | 訓練データの多様化、バイアス監査 |
| 回避型 | FN | パラフレーズで検出回避 | セマンティック分析、ハイブリッド設計 |
| 陳腐化型 | FN | 新手法の違反が検知不可 | 定期更新、ドリフト監視 |
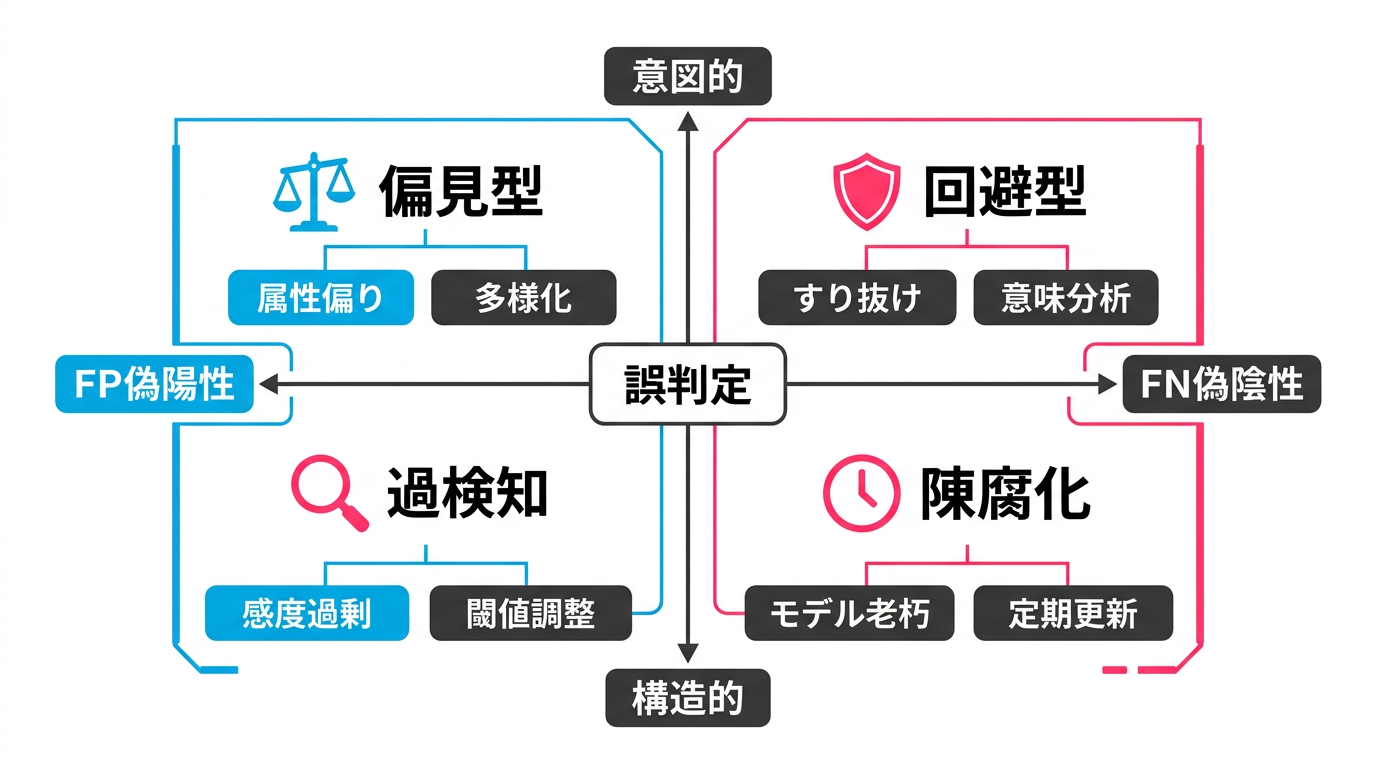 図1: 誤判定の4パターンを構造的・意図的の2軸で分類
図1: 誤判定の4パターンを構造的・意図的の2軸で分類
FPとFNのコスト非対称性
誤判定対応の設計で最初に決めるべきは、FPとFNのどちらがビジネスにとってより深刻かという優先順位です。
ドメイン別コスト非対称性
コスト非対称性はドメインごとに大きく異なります。
| ドメイン | FPのコスト | FNのコスト | 優先方向 |
|---|---|---|---|
| 医療診断 | 不要な検査・患者の不安 | 疾患見逃し→重症化 | FN回避(閾値下げ) |
| AML/不正検知 | アナリストの調査コスト | 不正見逃し→罰金・信用失墜 | FN回避(閾値下げ) |
| 広告審査 | 合法広告の配信停止→売上損失 | 違法広告配信→法的リスク | やや FN回避 |
| ECレビュー | 正当レビュー削除→ユーザー離脱 | やらせレビュー放置→信頼低下 | バランス型 |
| 子供向け | 安全コンテンツ削除 | 有害コンテンツ露出 | 強くFN回避 |
閾値調整の原則
コスト非対称性に基づいて、判定閾値を調整します。
FNコスト > FPコスト → 閾値を引き下げ(例: 50% → 30%)
→ 陽性判定を増やす → FPは増えるがFNは減る
FPコスト > FNコスト → 閾値を引き上げ(例: 50% → 70%)
→ 陽性判定を慎重に → FNは増えるがFPは減る
Claude 4.6 Sonnetの構造化出力を活用すれば、判定結果と同時に信頼度スコアを0〜100で返させることができます。この信頼度スコアが後述のルーティング設計の基盤になります。
信頼度スコアによる3層ルーティング設計
誤判定対応の核心は、信頼度スコアに基づいてケースを適切な処理層に振り分けるルーティング設計です。
3層モデル
2026年のベストプラクティスは、完全自動・AIエージェント再レビュー・人間専門家の3層構造です。
| 層 | 処理主体 | 対象 | 応答目標 | 処理割合 |
|---|---|---|---|---|
| L1 | AI自動判定 | 信頼度95%以上 | リアルタイム | 70〜85% |
| L2 | AIエージェント再レビュー | 信頼度70〜95% | 数分〜20分 | 10〜20% |
| L3 | 人間専門家 | 信頼度70%未満 | 4〜24時間 | 5〜10% |
L1(完全自動): 信頼度が十分に高いケースは自動で承認・却下します。全体の70〜85%がここで処理されるため、人間の負荷を大幅に削減できます。
L2(AIエージェント再レビュー): 2026年の新パラダイムです。グレーゾーンのケースを別のLLM(または同じLLMの別プロンプト)で再判定します。Anthropicのclaude code reviewでは、複数AIエージェントがPRを並列検査し、検出事項をフィルタリング→重大度ランク付けすることでFPを大幅に削減しています。
L3(人間専門家): 低信頼度ケース、規制関連の判断、L2で判定が割れたケースは人間の専門家が最終判断します。Gartnerは2026年までに企業の生成AIアプリの90%に正式なHITLプロセスが必須になると予測しています。
図2: 3層エスカレーションフロー ― AI自動判定から人間専門家までの振り分け設計
動的閾値の設計
閾値は固定値ではなく、コンテキストに応じて動的に調整するのが理想です。
- コンテンツタイプ別: 広告テキスト(閾値85%)vs ユーザー投稿画像(閾値75%)
- 時間帯別: 深夜帯はL3対応者が少ないため、L2の処理範囲を拡大
- トレンド連動: 社会的関心が高いトピックは閾値を下げて慎重に
- ユーザーレピュテーション: 過去の違反歴に応じて閾値を調整
// 動的閾値の設計例(疑似コード)
function getThreshold(context: ReviewContext): ThresholdConfig {
let l1Threshold = 0.95; // デフォルト
let l2Threshold = 0.70;
// コンテンツタイプによる調整
if (context.contentType === 'child_safety') {
l1Threshold = 0.99;
l2Threshold = 0.85;
}
// 時間帯による調整(深夜はL2の範囲を拡大)
if (context.isOffHours) {
l2Threshold = 0.60;
}
// ユーザーの過去違反歴
if (context.userViolationCount > 3) {
l1Threshold = 0.98;
l2Threshold = 0.80;
}
return { l1Threshold, l2Threshold };
}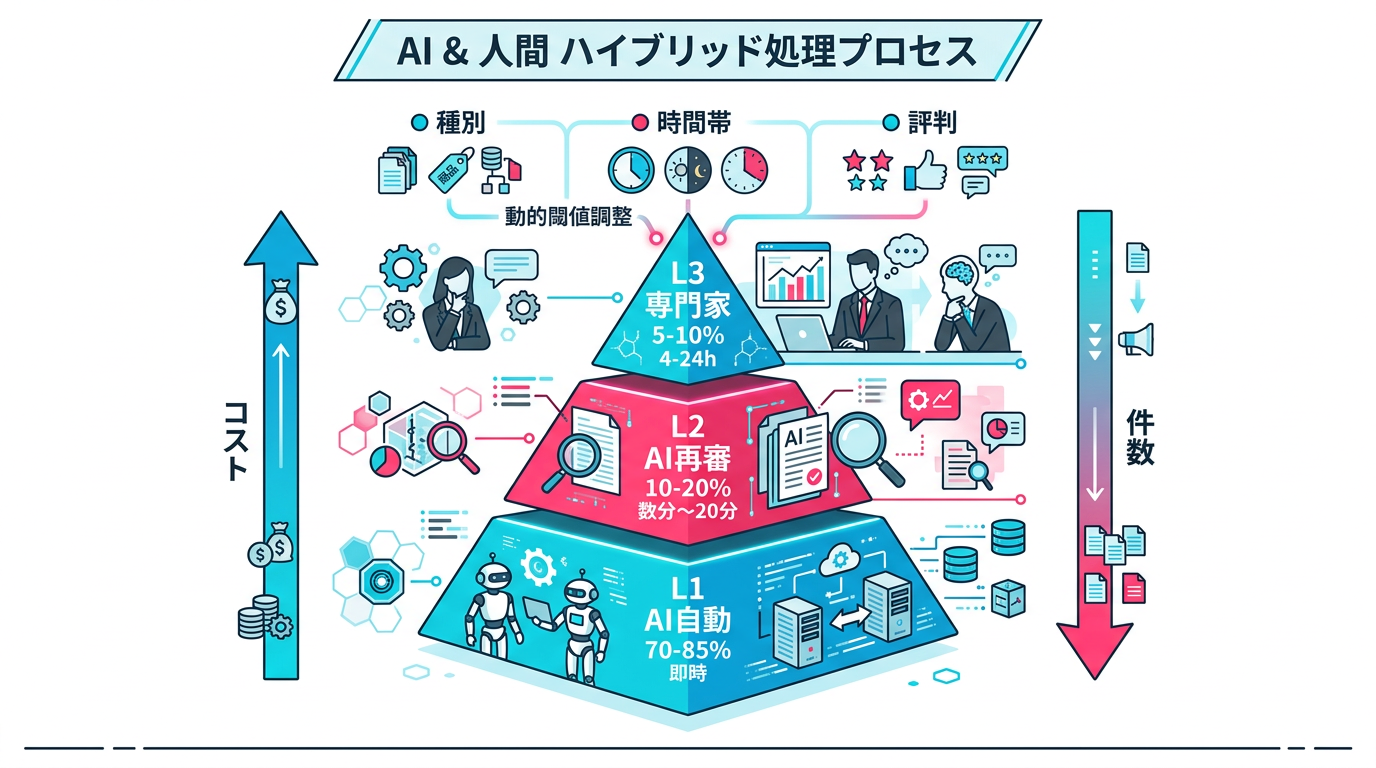 図3: 3層ルーティングモデルの全体設計
図3: 3層ルーティングモデルの全体設計
エスカレーションフローの設計テンプレート
3層ルーティングを実運用に落とし込むには、SLA(対応時間目標)とエスカレーション発動条件を明確に定義する必要があります。
SLA設計
| 優先度 | 対応時間目標 | エスカレーション発動 | 適用場面 |
|---|---|---|---|
| P1: 緊急 | 1時間以内 | 45分で通知、60分で再割当 | 法的リスク・安全性関連のFN |
| P2: 高 | 4時間以内 | 3時間で通知 | 高額取引・重要コンテンツのFP |
| P3: 中 | 12時間以内 | 9時間で通知 | 一般的なFP/FN是正 |
| P4: 低 | 24〜48時間 | 翌営業日 | 軽微な分類ミス |
実績データでは、エスカレーションアラートの導入だけでSLA違反を35%削減できたという報告があります。人員を増やさなくても、適切なアラート設計で対応速度は大きく改善します。
AI-over-AI: 2026年の新パラダイム
従来のHuman-in-the-Loop(HITL)は、処理量の増大に対してスケールしない問題がありました。2026年のトレンドは、AIによるAI監視(AI-over-AI)です。
CollabEval(Amazon Science)のアプローチでは、3つの独立したAIエバリュエーターが個別に評価を行い、協調ディスカッションを経て最終判定を出します。単一LLMの限界(一貫性のない判断、事前学習バイアス)を、複数エージェントの合議で補う設計です。
[対象コンテンツ]
├─ Agent A (Claude 4.6 Sonnet) ──→ 判定A
├─ Agent B (GPT-5.4) ──→ 判定B
├─ Agent C (Gemini 3.1) ──→ 判定C
│
└─ [合議ステップ]
├─ 全一致 → 確定
├─ 多数決 → 少数派の理由を記録して確定
└─ 全不一致 → 人間エスカレーション
この設計はルールベース×LLMハイブリッド設計の発展形とも言えます。ルール判定で明確なケースを先にフィルタし、残りのグレーゾーンを複数エージェントで処理する多段構成が最も効率的です。
マルチエージェント審査のコスト目安: Anthropicのclaude code reviewでは1レビューあたり$15〜25、所要時間約20分で、PRの54%に実質的なコメントを出せています(従来手法の16%から3.4倍向上)。審査業務でも同様の費用対効果が期待できます。
異議申立(アピール)プロセスの構築
誤判定への対応は社内のエスカレーションだけでなく、外部ユーザーからの異議申立にも対応する必要があります。EU DSAの施行以降、プラットフォームに対してアピールプロセスの整備が義務化される流れが加速しています。
アピールプロセスの5ステップ
ステップ1: 異議受付 — ユーザーが判定結果に対して異議を申立てる窓口を設置します。判定通知メールやダッシュボード上にワンクリックでアピールできるボタンを配置します。
ステップ2: 自動スクリーニング — 明らかに無効なアピール(判定から90日以上経過、同一案件の重複申立など)を自動でフィルタリングします。
ステップ3: 二次審査 — L2またはL3の審査者が、元の判定根拠とユーザーの異議内容を比較レビューします。ここでは初回判定とは別の審査者が担当することが重要です。
ステップ4: 結果通知 — 審査結果と理由を明確に伝えます。説明可能なAI(XAI)の技術を活用し、「なぜこの判定になったか」を具体的に説明します。
ステップ5: 記録と分析 — アピールの結果(維持/覆し)をすべてログに記録し、定期的にパターン分析を行います。覆し率が高い判定カテゴリは、モデルの改善対象として優先します。
覆し率のベンチマーク
EU DSAの統計は、アピールプロセスの重要性を示す強力なデータです。
- 2025年上半期のモデレーション判定: 90億件以上(99%がAIによるプロアクティブ検知)
- 内部アピール件数: 1.65億件以上 → 約30%が覆し
- 域外紛争解決機関: 1,800件以上 → 52%が覆し
- EU Appeals Centre全体: ユーザー有利の覆しが75%以上
内部アピールの30%が覆されるという事実は、AIモデレーションの精度がまだ十分ではないことを示しています。同時に、適切なアピールプロセスがあれば誤判定を修正できることも意味しています。
フィードバックループで継続改善する仕組み
誤判定対応の最終目標は、同じ間違いを繰り返さないことです。そのためには、修正データをモデル改善に反映するフィードバックループの構築が不可欠です。
継続学習パイプライン
[AI判定] → [人間レビュー/修正] → [修正ログ蓄積]
↑ │
│ ▼
│ [パターン分類・分析]
│ │
│ ▼
└──────────────── [プロンプト改善/ファインチューニング]
フィードバックループの構成要素は5つです。
1. 修正データ収集: 人間が修正した判定結果を教師データとして蓄積します。「元の判定」「修正後の判定」「修正理由」の3つを必ず記録します。審査ログの活用と連携させることで、分析の精度が上がります。
2. パターン分類: 修正データをNG理由ごとに分類します。Claude 4.6 SonnetのようなLLMを使えば、自由記述の修正理由を自動でカテゴリ分類できます。
3. 根本原因分析: 分類結果から、誤判定の根本原因を特定します。プロンプトの問題か、入力データの変化か、新しい違反パターンの出現か。
4. 改善実施: 原因に応じて対策を打ちます。プロンプトの修正、Few-shot例の追加、閾値の調整、ルールの追加など。
5. 効果検証: 改善後の精度を検証します。A/Bテストで改善前後を比較し、改善効果を定量的に確認します。
アクティブラーニングの活用
2026年のフィードバックループで注目されているのがアクティブラーニングです。AIが最も「不確実」と感じるデータポイントを選択的に人間に提示し、アノテーションの効率を最大化する手法です。
従来のランダムサンプリングでは、AIがすでに正しく判定できるケースにも人間のレビュー時間を使っていました。アクティブラーニングでは、信頼度スコアが閾値付近のケース(最も判断が難しいケース)に集中してレビューリソースを投入するため、少ないレビュー数で大きな精度向上が得られます。
モデル崩壊に注意: AI生成データのみでモデルを再訓練すると、「モデル崩壊」(model collapse)が発生するリスクがあります。人間がアノテーションした高品質なデータをフィードバックループに組み込むことで、この問題を防げます。2025年時点でRLHF/DPOを採用する企業は70%に達しています。
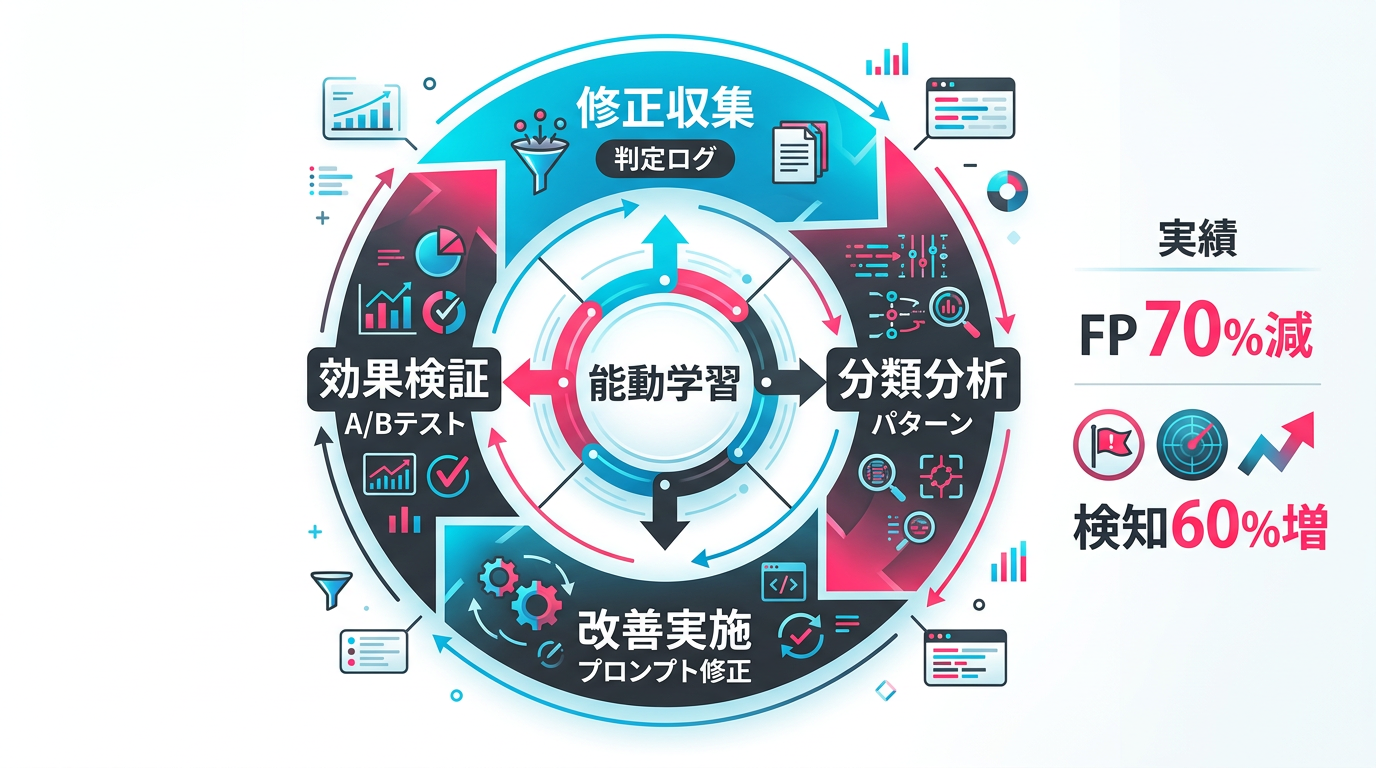 図4: 修正データを活用した継続改善サイクルの全体像
図4: 修正データを活用した継続改善サイクルの全体像
実践ケーススタディ: 業界別の改善実績
AML(マネーロンダリング対策)
AML分野はAI誤判定対応の先進事例が豊富です。従来のルールベースシステムではFP率が90〜95%という驚異的な数値でした。つまり、アラートの9割以上が「空振り」です。
AIの導入により、この状況は劇的に改善しています。
- Tookitaki SAMを導入したグローバル銀行: 6アラート中1件がSAR(疑わしい取引報告)に結びつく効率を達成(運用効率600%改善)
- シンガポールのTier1銀行: 個人名照合のFP70%削減、法人名照合のFP60%削減
- トランザクション監視: TP予測率96%を達成しながらFP50%削減
コンテンツモデレーション
EU DSA施行後2年間で5,000万件以上の判定が覆されています。プラットフォーム側も、AI判定の限界を認識し、アピールプロセスの改善に注力しています。
Facebook/Instagramでは、制限商品カテゴリのアピール覆し率が65%、ヌードカテゴリが57%、ヘイトスピーチカテゴリが50%(EU Appeals Centre統計)。カテゴリによって誤判定の傾向が大きく異なることがわかります。
コードレビュー
ソフトウェア開発分野でも、AIレビューの誤判定対応が進んでいます。Claude Code Reviewでは、複数エージェントによるFPフィルタリングにより、PRの54%に実質的なコメントを出せるようになりました(旧手法では16%)。全体として本番バグ62%削減、レビュー時間40%節約を達成しています。
まとめ
AI審査の誤判定対応は、「AIの精度を上げる」だけでは解決しません。以下の5つの要素を組み合わせたシステム設計が必要です。
- パターン分類: 誤判定を4パターンに分類し、原因ごとに対策を打つ
- コスト分析: FPとFNのコスト非対称性を定量化し、閾値を最適化する
- 3層ルーティング: 信頼度スコアに基づいてL1→L2→L3に適切に振り分ける
- アピールプロセス: 外部ユーザーからの異議申立に体系的に対応する
- フィードバックループ: 修正データをモデル改善に反映する継続改善サイクルを回す
品質モニタリング体制と連携させることで、誤判定の早期検知が可能になります。AI導入の6フェーズのフェーズ4〜5で、ここで解説したエスカレーション体制を構築することを推奨します。
よくある質問
AI審査の誤判定率はどのくらいが正常ですか?
業界やタスクにより異なりますが、一般的なコンテンツモデレーションでは有害コンテンツの約88%を正確にフラグでき、AIがフラグしたケースの5〜10%が人間レビューを必要とします。AML分野では従来FP率90〜95%でしたが、最新AIで10〜30%まで削減された事例があります。重要なのは絶対値より改善トレンドです。
False PositiveとFalse Negativeのどちらを優先すべきですか?
ドメインによって異なります。医療診断や子供向けプラットフォームではFN(見逃し)のコストが圧倒的に高いため、閾値を下げてFP(過検知)を許容します。逆にECの商品審査ではFP(合法商品のブロック)が直接売上損失になるため、閾値を上げてFPを減らします。コスト非対称性を定量化してから設計してください。
エスカレーション体制に何人必要ですか?
処理量と対応時間のSLAによります。目安として、AIが処理の70〜85%を自動判定し、10〜20%をAIエージェント再レビュー、残り5〜10%を人間専門家が担当する3層モデルが標準です。月間1万件の審査なら、L3人間レビュアーは2〜3名で回ります。Gartnerは2026年までに企業の生成AIアプリの90%に正式なHITLプロセスが必須になると予測しています。
フィードバックループはどう構築すべきですか?
人間が修正した判定結果を教師データとして蓄積し、プロンプト改善やファインチューニングに活用するサイクルを回します。具体的には、修正ログの収集→NG理由の分類→パターン分析→プロンプト改善→精度検証の5ステップです。アクティブラーニングを組み合わせ、AIが最も不確実なケースを優先的に人間に提示すると、少ない修正データで効率的にモデルを改善できます。

この記事の著者
Naosy 編集部
レビュー・校正・審査プロセスの最適化に関する実践的なナレッジを発信しています。



