AI翻訳チェックの実践ガイド ― 品質を担保する3段階レビューフローと自動評価手法
AI翻訳の品質を担保するための3段階レビューフローを解説。BLEU・COMET・LLM-as-Judgeの自動評価手法から、ネイティブレビューとの組み合わせまで、多言語コンテンツの品質管理を実践的に紹介します。
「DeepLで翻訳したので、そのまま使ってください」――この一言で、海外向けプレスリリースに致命的な誤訳が混入した。 私たちが支援した企業で実際に起きた事例です。AI翻訳の精度は2025年以降飛躍的に向上していますが、「そのまま使える品質」と「公開できる品質」の間にはまだ大きなギャップがあります。
AI翻訳は「下訳」としては十分な品質に達しています。問題は、その下訳をどうチェックし、公開品質まで引き上げるかのプロセスが確立されていないことです。この記事では、AI翻訳の品質を体系的にチェックするための3段階レビューフローと、翻訳品質を自動で評価する最新技術を解説します。
なぜAI翻訳の「そのまま使い」は危険なのか
AI翻訳の精度は年々向上しています。DeepLやGoogle翻訳はもちろん、Claude 4.6 Sonnet、GPT-5.4、Gemini 3.1といった最新のLLMも翻訳タスクで高い性能を発揮します。WMT(機械翻訳の国際評価コンペティション)2024年大会では、LLMが11言語ペア中9つで従来の専用翻訳エンジンを上回り、2025年以降はさらにその差が広がっています。それでも「そのまま公開」が危険な理由は、AI翻訳が特定のカテゴリのエラーを系統的に見逃すからです。
エラーカテゴリ1: 専門用語の誤訳
AI翻訳は一般的な語彙では高精度ですが、業界固有の用語を正しく訳せない場合があります。たとえば医薬品の「有効成分」を"active ingredient"ではなく"effective component"と訳す、金融用語の「引当金」を"reserve"ではなく"allocation"と訳す、といったケースです。専門用語の誤訳は、読者の信頼を一瞬で失います。
エラーカテゴリ2: ニュアンスの喪失
日本語の婉曲表現や敬意表現は、AI翻訳で失われやすい要素です。「ご検討いただけますと幸いです」が"Please consider"に変換されると、元の丁寧さが消えます。BtoBのメールやプレスリリースでは、このニュアンスの違いがビジネス上の問題になることがあります。
エラーカテゴリ3: 文化的な不適切さ
言語的には正しくても、対象国の文化やビジネス慣習に合わない表現が生まれることがあります。色の象徴性(白は日本では清潔、中国では喪を連想する場合がある)、数字の忌避(4は日本語圏で避けられる)、ジェスチャーの意味の違いなど、AI翻訳は文化的な文脈を考慮できません。
AI翻訳の使いどころ
AI翻訳が「そのまま使える」のは、社内の参考資料や議事録のような非公開文書に限られます。顧客向けの文書、マーケティング素材、法的文書、技術マニュアルなど、公開・外部配布する文書には必ずレビュープロセスを経てください。
翻訳品質の「3階層モデル」― 何をチェックするかを整理する
AI翻訳のチェックを効率化するために、私たちは翻訳品質を3つの階層で整理する「3階層モデル」を使っています。このモデルは、MQM(Multidimensional Quality Metrics、翻訳品質の国際評価フレームワーク)を審査業務向けに再構成したものです。
第1階層: 正確性(Accuracy)
原文の意味が正しく伝わっているか。誤訳、訳抜け、数値の間違いをチェックします。AI翻訳が最も頻繁にエラーを起こすのがこの階層で、特に否定文の肯定への変換、条件文の誤訳、数値と単位の不一致に注意が必要です。
第2階層: 流暢性(Fluency)
訳文がターゲット言語として自然に読めるか。文法エラー、不自然な語順、ぎこちない表現をチェックします。AI翻訳は文法的に正しい文を生成する能力が高いため、この階層のエラーは比較的少ないですが、「翻訳調」の不自然さが残ることがあります。
第3階層: 適切性(Adequacy)
対象読者・媒体・目的に合った訳文になっているか。トーン(丁寧さのレベル)、用語の統一性、ブランドボイスの維持、文化的な適合性をチェックします。この階層はAIによる自動チェックが最も難しく、人間のレビューが不可欠な領域です。
3階層モデルの重要なポイントは、下の階層が満たされていなければ上の階層のチェックは意味がないということです。正確性に問題がある翻訳の流暢性を評価しても無駄です。チェックは必ず正確性→流暢性→適切性の順で行います。
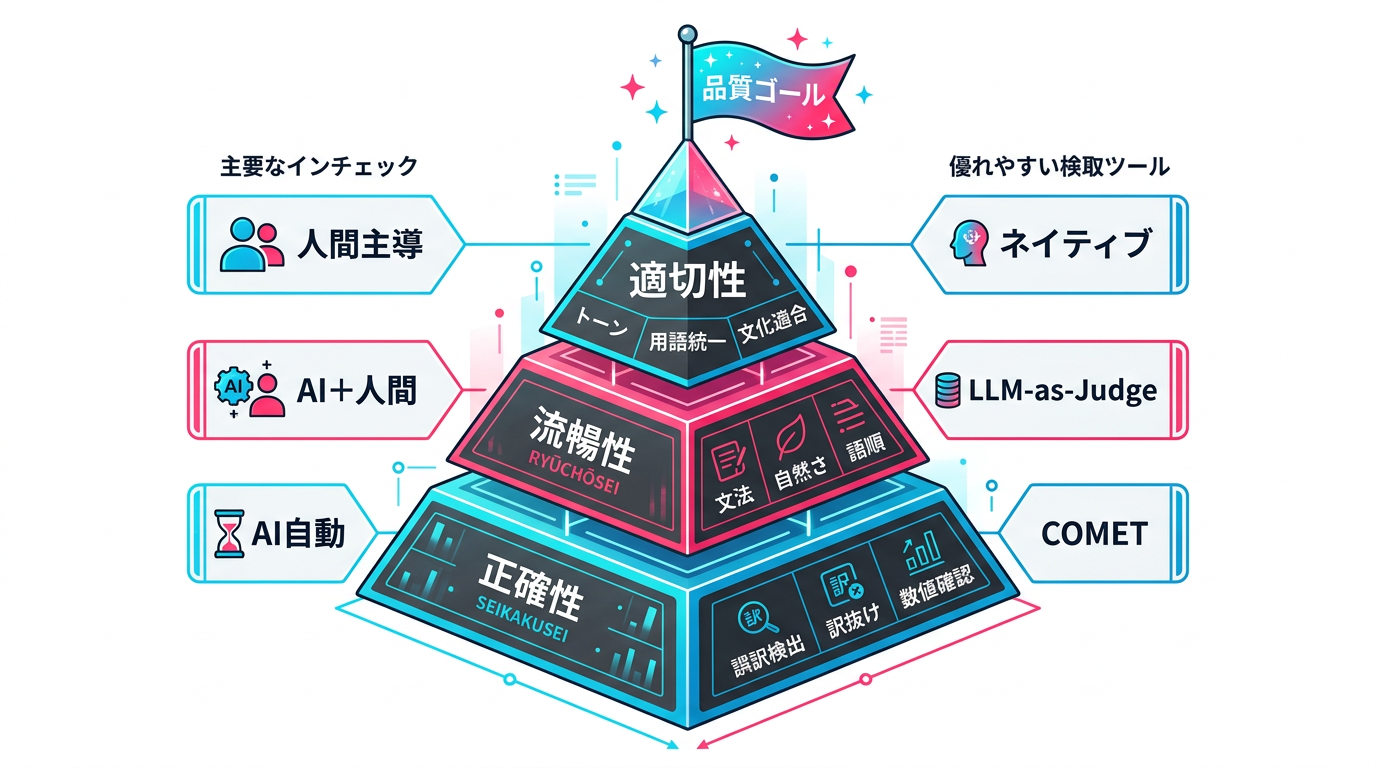 図2: 翻訳品質の3階層モデル ― 正確性・流暢性・適切性
図2: 翻訳品質の3階層モデル ― 正確性・流暢性・適切性
AI翻訳チェックの3段階レビューフロー
3階層モデルに基づき、AI翻訳の品質チェックを実務に組み込むための3段階レビューフローを設計しました。
Stage 1: AI自動評価 ― 問題箇所の一次スクリーニング
最初のステップは、AIを使って翻訳品質を自動的に評価し、人間がレビューすべき箇所を絞り込むことです。ここで使う技術は大きく2つあります。
自動評価スコアによるスクリーニング
COMET(Crosslingual Optimized Metric for Evaluation of Translation)は、2025年現在、最も人間の評価と相関が高い自動翻訳評価指標です。原文・参照訳・AI翻訳の3つを入力すると、0〜1のスコアを返します。スコアが0.85以上なら高品質、0.7〜0.85なら要確認、0.7未満なら要修正と判断します。
従来よく使われていたBLEU(Bilingual Evaluation Understudy)は、単語の一致率をベースとした指標ですが、言い換えや同義語を評価できない弱点があります。文章チェックの自動化で解説しているチェック項目の設計と同様、翻訳チェックでも「何を測っているか」を理解した上で指標を選ぶことが重要です。
LLM-as-Judgeによる詳細チェック
COMETスコアが低い箇所や、重要度の高い文書に対しては、LLMを「翻訳品質の審査員」として使います。具体的には、Claude 4.6 SonnetやGPT-5.4に原文と訳文を入力し、「正確性」「流暢性」「適切性」の3軸で評価させます。2026年現在のLLMは200Kトークン以上のコンテキストウィンドウを持つため、長文の翻訳でも文書全体の一貫性を保った評価が可能です。
LLM-as-Judgeの利点は、スコアだけでなく「なぜ問題があるか」の理由を自然言語で説明できることです。「第3段落の"検討する"が"examine"と訳されていますが、ビジネス文脈では"consider"が適切です」といった具体的なフィードバックが得られます。
Stage 2: 専門レビュー ― 用語と業界ルールの照合
AI自動評価で品質スコアが確認できたら、次は業務固有の品質基準に照らしたレビューです。
用語集(ターモロジー)との照合
企業ごとに定めている用語集と訳文を照合します。同じ原文が文書内で異なる訳語になっていないか、ブランド固有の表現が正しく使われているかを確認します。この工程はルールベースのチェックで自動化しやすく、翻訳管理ツール(TMS)の多くがこの機能を備えています。
業界固有のルール照合
製薬業界なら各国の薬事規制に準拠した表現か、金融業界なら免責事項が適切に翻訳されているか、法務文書なら契約条件の意味が変わっていないか。AIコンプライアンス体制の構築ガイドで触れているように、規制対応が必要な文書では、業界固有のチェック基準を明示的に設計する必要があります。
Stage 3: ネイティブ確認 ― 自然さと文化適合性の最終チェック
最後のステップは、ターゲット言語のネイティブスピーカーによる確認です。AIでは検出が難しい「自然さ」と「文化的な適合性」をチェックします。
重要なのは、ネイティブレビューの範囲を事前に限定することです。AI自動評価と専門レビューを経た後のネイティブ確認は、「読んで違和感がないか」に集中できます。すべてのチェックをネイティブに任せると、コストと時間が膨れ上がるため、Stage 1と2で品質の底上げをしておくことが前提です。
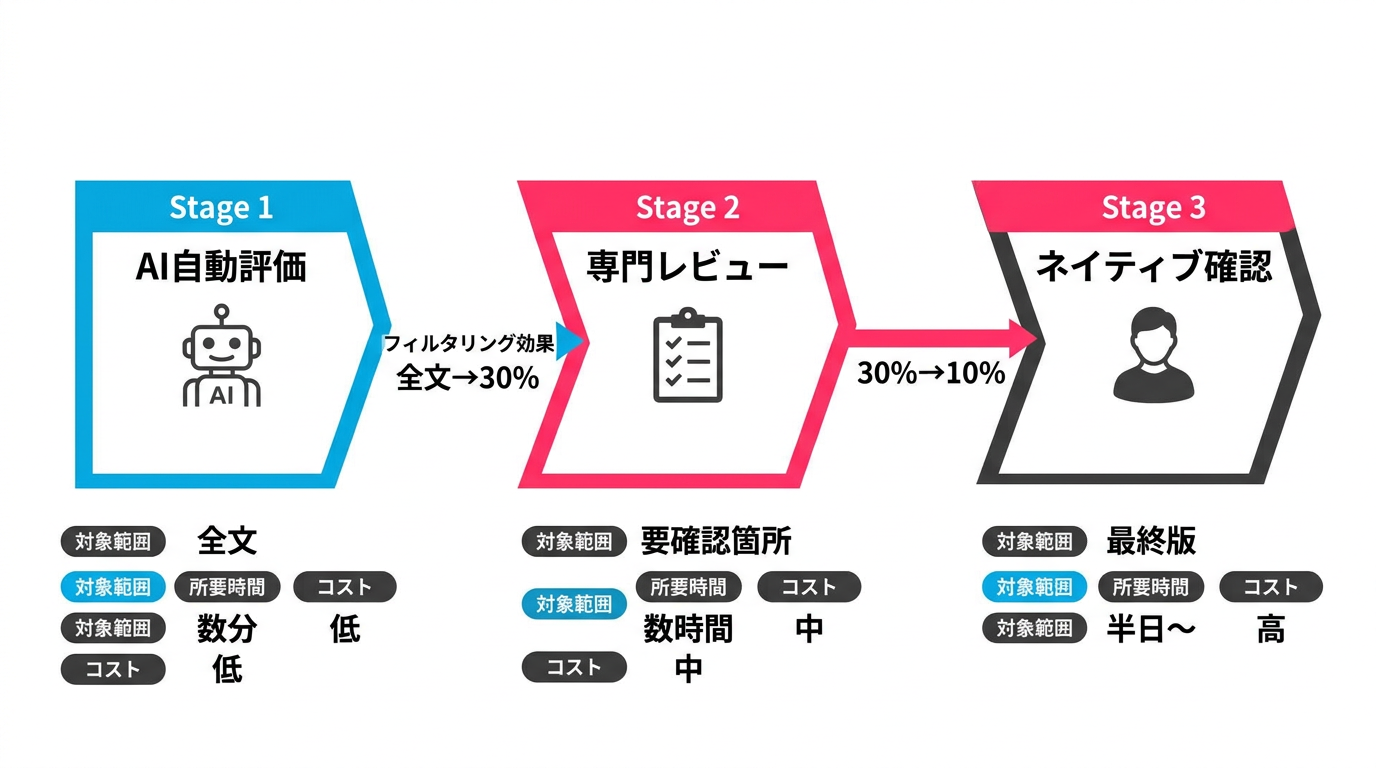 図3: 3段階レビューフローのフィルタリング効果
図3: 3段階レビューフローのフィルタリング効果
翻訳品質を自動評価する技術 ― BLEU・COMET・LLM-as-Judge
翻訳品質の自動評価技術は、2025年以降大きく進化しています。従来のBLEUに代わり、ニューラルベースの指標が主流になりつつあります。
BLEU(Bilingual Evaluation Understudy)
最も歴史のある自動翻訳評価指標で、訳文と参照訳の単語・フレーズの一致率を測定します。計算が高速で、大量のテキストを一括評価できるのが利点です。ただし、同じ意味の異なる表現(「検討する」→"consider"と"examine")を区別できない大きな限界があります。参照訳が1つしかない場合はスコアが不当に低く出るため、2026年現在では翻訳品質の唯一の指標として使うべきではありません。
COMET(Crosslingual Optimized Metric for Evaluation of Translation)
ニューラルネットワークベースの評価指標で、原文・訳文・参照訳の3入力から品質スコアを算出します。人間の品質判断との相関がBLEUを大きく上回り、言い換えや同義語の使用も適切に評価できます。最新のxCOMET(eXplainable COMET)は、エラー箇所を「minor / major / critical」の3段階で特定しながらスコアを算出するため、「どこが問題か」まで分かる評価が可能です。日本語を含む多言語ペアで高い精度を達成しており、WMT2024ではCOMET-22を上回る相関を示しました。
LLM-as-Judge
LLMに翻訳品質の評価者(Judge)の役割を与え、原文と訳文のペアを入力して品質評価させる手法です。2025年以降、この手法が急速に実用化されました。利点は3つあります。
- 多角的な評価: 正確性・流暢性・適切性を同時に評価し、各軸のスコアと理由を出力できる
- 参照訳が不要: BLEUやCOMETと異なり、正解の訳文がなくても評価が可能。実務ではすべての文に参照訳を用意するのは現実的でないため、大きな利点
- カスタマイズ性: 「製薬業界の用語に照らして評価してください」「カジュアルなトーンが維持されているか確認してください」といった業務固有の評価基準をプロンプトで指定できる
コストの面では、COMETがローカルで実行可能(無料)なのに対し、LLM-as-JudgeはAPI呼び出しのたびに費用がかかります。ただし2026年現在、Claude 4.6 Sonnetのような高性能モデルのAPI費用は大幅に下がっており、1,000文の評価でも数百円程度です。実務では、COMETで全文をスクリーニングし、低スコアの箇所だけLLM-as-Judgeで詳細評価する二段構えが費用対効果の高いアプローチです。さらに、マルチエージェント翻訳パイプライン(複数のLLMが翻訳・評価・修正を分担する仕組み)も実用化が進んでおり、翻訳品質チェックの自動化はますます高度化しています。
実務で使える翻訳品質チェックツールと選び方
翻訳品質チェックの実務では、翻訳管理システム(TMS)、LLM、専用ツールを組み合わせて使うのが一般的です。
翻訳管理システム(TMS)
Phrase(旧Memsource)やmemoQなどのTMSは、翻訳メモリ(過去の翻訳資産を蓄積・再利用する仕組み)と用語管理機能を備えており、用語の統一性チェックを自動化できます。2025年以降、これらのツールはLLMを組み込んだ品質チェック機能を追加しています。
LLMの直接活用
生成AIの業務活用パターンで紹介しているチェックパターンは、翻訳品質チェックにも応用できます。Claude 4.6 OpusやGPT-5.4 Proに「翻訳品質レビューア」の役割を与え、原文と訳文のペアを入力して評価させます。2026年のLLMはシステムプロンプトで評価基準を詳細に定義でき、業界固有の用語集や過去の修正履歴をコンテキストに含めることで、企業ごとにカスタマイズされた品質チェックが可能です。
QAツール
Xbench(翻訳品質保証ツール)やVerifika(多言語QAツール)は、数値の不一致、タグの破損、用語集違反、スペルチェックなどのルールベースのチェックを自動実行します。LLMが苦手な機械的なチェック(数値・記号・フォーマット)を補完する役割として、LLM-as-Judgeと併用すると効果的です。
選定のポイントは、翻訳のボリュームと頻度です。月に数件の翻訳チェックならLLMの直接利用で十分ですが、日常的に大量の多言語コンテンツを扱うなら、TMSとQAツールの組み合わせが運用コストを下げます。マルチモーダルAIの活用で解説しているように、画像内テキストの翻訳チェックにはマルチモーダルLLMも有効です。
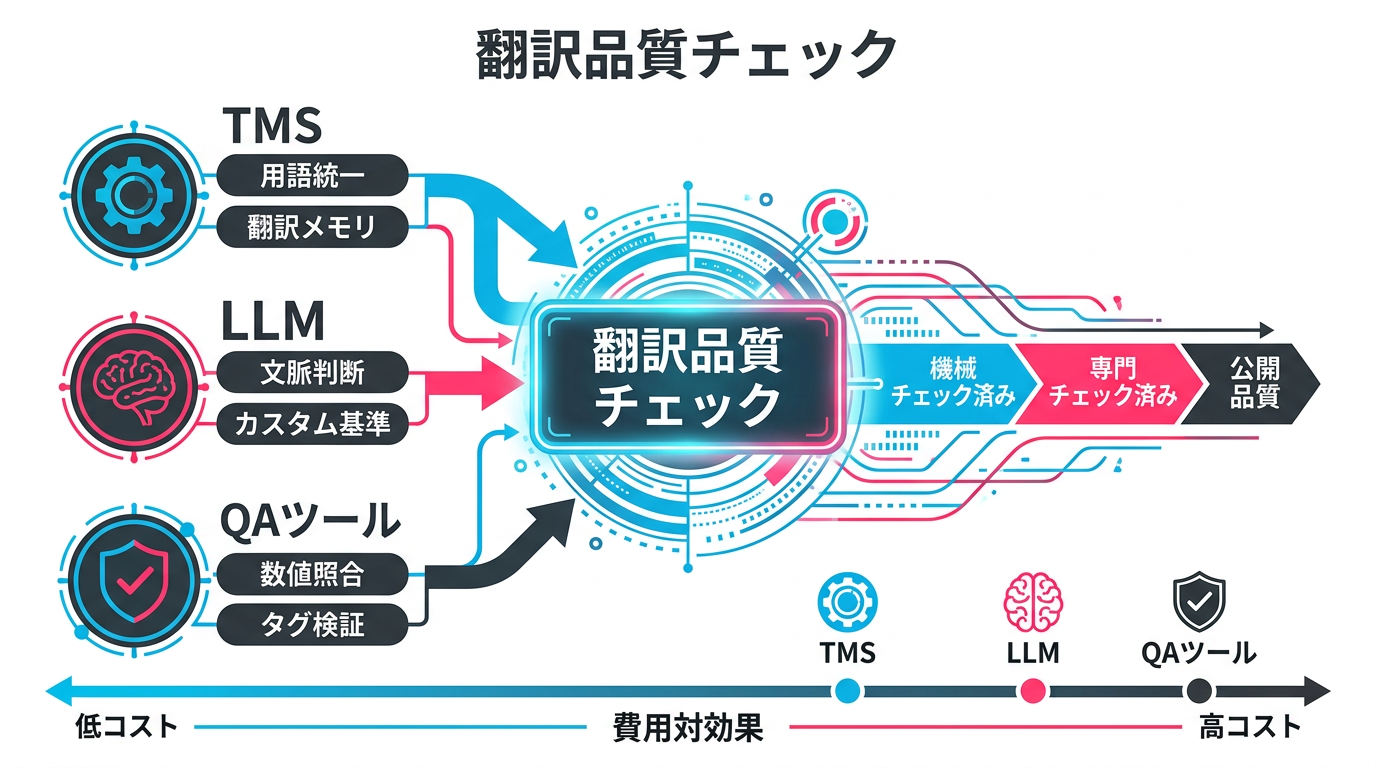 図4: ツール選定の考え方 ― TMS・LLM・QAツールの役割分担
図4: ツール選定の考え方 ― TMS・LLM・QAツールの役割分担
まとめ
AI翻訳の品質チェックは、「全部人間がやる」でも「AI任せ」でもなく、3段階のレビューフローで段階的にフィルタリングするのが最も効率的です。
- 3階層モデルで品質基準を設計する: 正確性→流暢性→適切性の順にチェック。下の階層が満たされなければ上のチェックは無意味
- Stage 1(AI自動評価)で全文をスクリーニング: COMETスコアで品質の底上げを確認し、低スコア箇所をLLM-as-Judgeで詳細チェック
- Stage 2(専門レビュー)で業界ルールを照合: 用語集との照合と業界固有の規制チェックを実施
- Stage 3(ネイティブ確認)は範囲を限定: Stage 1・2で品質が確保された最終版に絞って確認し、コストを最適化
次のアクションとして、自社で翻訳が必要な文書を「公開文書」と「社内参考資料」に分類してください。公開文書には3段階フロー、社内参考資料にはStage 1のAI自動評価のみ、というように使い分けることで、限られたリソースで翻訳品質を最大化できます。
よくある質問(FAQ)
AI翻訳をそのまま公開しても大丈夫ですか?
推奨しません。AI翻訳は文法的に正しくても、業界用語の誤訳、ニュアンスの違い、文化的に不適切な表現が含まれるリスクがあります。最低でもLLMによる自動チェックと、重要文書にはネイティブレビューを組み合わせてください。
AI翻訳の品質チェックにはどのくらい時間がかかりますか?
自動評価だけなら数秒〜数分で完了します。人間によるネイティブレビューを含めても、ゼロから翻訳する場合と比べて60〜70%の時間短縮が見込めます。ポストエディットの工数は、AI翻訳の品質によって大きく変わります。
BLEU・COMET・LLM-as-Judgeのどれを使うべきですか?
2026年現在、LLM-as-Judgeが最も人間の評価に近い結果を出します。ただしAPI費用がかかるため、大量のテキストにはCOMETで一次スクリーニングし、低スコアの箇所だけLLM-as-Judgeで詳細チェックする組み合わせが実用的です。
社内に翻訳の専門家がいない場合でもAI翻訳チェックは可能ですか?
可能です。LLM-as-Judgeによる自動評価で品質スコアを取得し、問題のある箇所を特定できます。ただし最終的なネイティブチェックは外部の翻訳レビューサービスやクラウドソーシングで補うことを推奨します。

この記事の著者
Naosy 編集部
レビュー・校正・審査プロセスの最適化に関する実践的なナレッジを発信しています。



