食品メーカーの表示審査をAIで効率化 ― アレルゲン・栄養成分チェックの半自動化事例
食品表示法に基づくアレルゲン表記・栄養成分表示の審査をAIで半自動化した食品メーカーの導入事例を紹介します。OCR×ルールベース×LLMのハイブリッド審査で、審査時間60%削減・表示ミスゼロ継続を実現した取り組みと、2026年のマルチモーダルAIがもたらす次の進化を解説します。
「新商品のパッケージに印刷ミスがあり、アレルゲン表示が漏れていた」――この一件の事故で、回収費用は数千万円に達します。 食品メーカーにとって表示審査のミスは、消費者の健康被害に直結するだけでなく、ブランド毀損と経済的損失をもたらす最もリスクの高い品質事故の一つです。
食品表示法の施行以降、表示項目は増加の一途をたどっています。特定原材料8品目に加え、表示推奨の20品目を含む合計28品目のアレルゲン表示、栄養成分表示の義務化、遺伝子組換え表示の厳格化――審査担当者の負荷は年々増大しています。
この記事では、ある食品メーカーが表示審査をAIで半自動化し、審査時間60%削減と表示ミスゼロを継続している事例を紹介します。
A社の課題 ― 新商品ラッシュで表示審査がパンク
中堅食品メーカーのA社(従業員約800名、年間売上300億円規模)は、健康志向ブームに乗って年間200点以上の新商品・リニューアル品を投入しています。すべての商品パッケージは品質管理部門の表示審査を通過しなければ製造に進めません。
表示審査の具体的な負荷
A社の品質管理部門は6名体制。1商品あたりの表示審査に平均3時間、繁忙期は5時間以上かかっていました。
- 原材料の照合: 規格書に記載された原材料と、パッケージの一括表示欄の記載が一致しているか
- アレルゲンの網羅性: 原材料に含まれるアレルゲン(特定原材料8品目+推奨20品目)がすべて表示されているか
- 栄養成分の整合性: 原材料から計算した栄養成分値と、パッケージに表示された数値が許容誤差内か
- 強調表示の適切性: 「たんぱく質たっぷり」などの強調表示に、法定の基準値を満たしているか
- コンタミ表記: 製造ラインを共有する製品のアレルゲン混入可能性が適切に表示されているか
最大の問題は、審査のボトルネック化でした。 新商品の発売スケジュールが審査待ちで遅延するケースが月に3〜4件発生。審査の質も、担当者の疲労やスキル差で安定しませんでした。
消費者庁の食品表示法違反事例は年間100件以上。アレルゲン表示の欠落による自主回収は毎年発生しており、1件あたりの回収コストは数百万〜数千万円に達します。表示審査のミスは「起きてはならないミス」です。
食品表示審査の難しさ
食品表示審査が他の審査業務と比べて特に難しい理由は3つあります。
難しさ1: 法令の複雑さと頻繁な改正
食品表示に関わる法令は食品表示法だけではありません。JAS法、健康増進法、景品表示法、食品衛生法が複合的に適用されます。さらに、消費者庁は毎年のようにガイドラインを更新しており、審査基準を常に最新に保つ必要があります。
2026年現在の主な規制動向として、遺伝子組換え表示制度の厳格化、食品添加物の表示方法の見直し、アレルゲン表示の対象品目拡大の議論が進んでいます。
難しさ2: チェック項目の多さと組み合わせ爆発
1つの商品パッケージに含まれるチェック項目は50以上あります。原材料名の表示順序(重量順)、アレルゲンの個別表示と一括表示の整合性、栄養成分8項目の数値、賞味期限の表示方法、製造者情報――これらをすべて人間が目視でチェックするのは、注意力の限界を超えています。
難しさ3: 暗黙知への依存
「この原材料名は業界的には別の呼び方もある」「この表現は景表法的にグレー」といった判断は、ベテラン審査者の経験に依存しています。プロンプト作成ガイドで解説した暗黙知の言語化が、食品表示の領域でも重要な課題です。
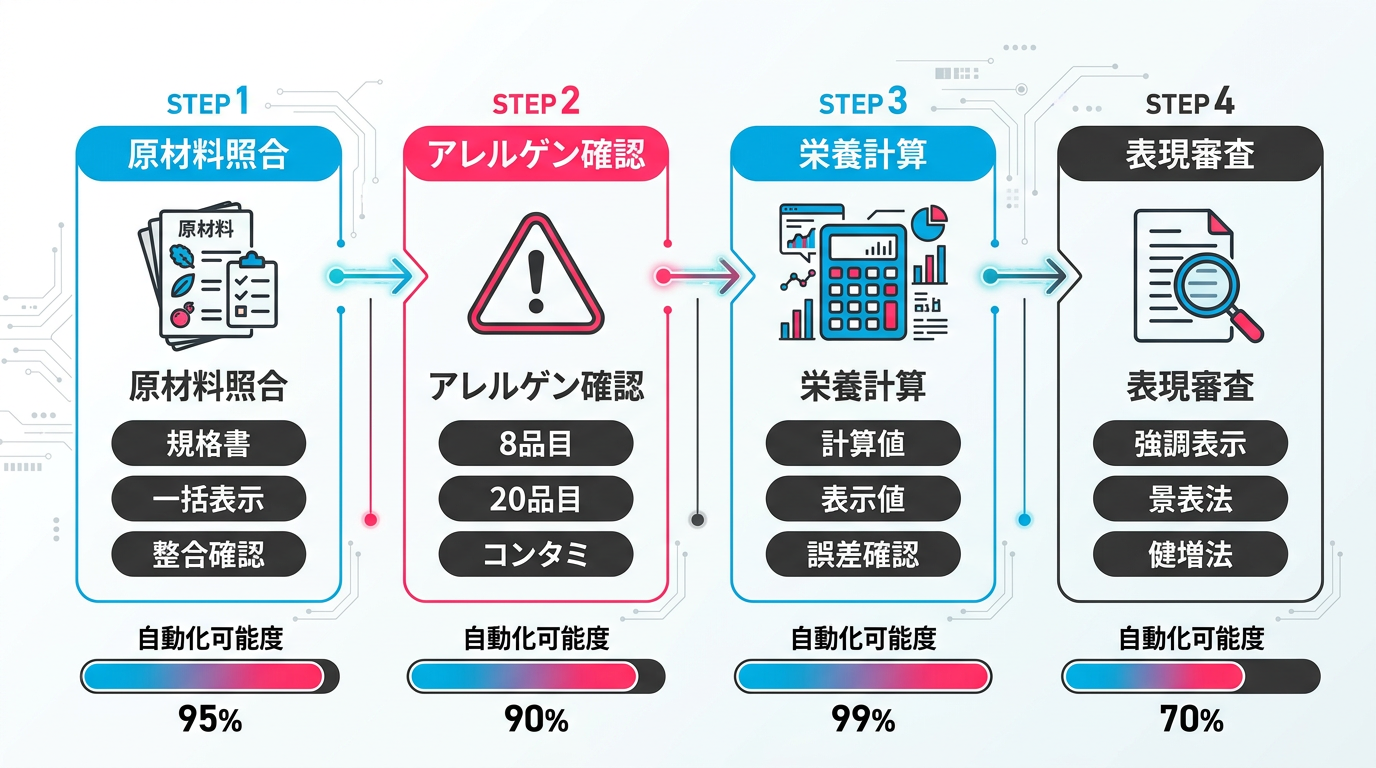 図1: 食品表示審査の4工程 ― 工程ごとの自動化ポテンシャル
図1: 食品表示審査の4工程 ― 工程ごとの自動化ポテンシャル
導入内容 ― OCR × ルールベース × LLMのハイブリッド審査
A社が構築した表示審査システムは、3つの技術を組み合わせたハイブリッド構成です。ルールベース×LLMハイブリッド設計の食品表示への具体的な適用事例と言えます。
レイヤー1: テキスト抽出(マルチモーダルAI)
パッケージデザインのPDFまたは画像からテキストを抽出します。A社は当初OCRを使用していましたが、2026年にGemini 3.1 Proのマルチモーダル機能に切り替えました。
従来のOCRでは背景模様との判別や縦書きテキストの処理に課題がありましたが、マルチモーダルAIは画像全体を「理解」するため、これらの問題が大幅に改善されました。特に栄養成分表示の表形式データの読み取り精度が、OCR単体の85%からマルチモーダルAIでは97%に向上しています。
# マルチモーダルAIによるパッケージ読み取りの指示例
以下のパッケージ画像から、食品表示法に基づく表示事項を
すべて構造化して抽出してください。
抽出項目:
- 商品名
- 原材料名(記載順)
- アレルゲン表示(個別表示・一括表示)
- 栄養成分表示(エネルギー、たんぱく質、脂質、炭水化物、食塩相当量)
- 内容量
- 賞味期限の表示方法
- 製造者情報
- 保存方法
レイヤー2: ルールベース照合
抽出したテキストデータを、事前定義したルールで照合します。
アレルゲン照合: 原材料リストから特定原材料8品目(えび、かに、小麦、そば、卵、乳、落花生、くるみ)と推奨20品目を自動検出し、一括表示欄の記載と突合。不足があれば即座にアラート。
栄養成分検証: 原材料の配合比率と栄養成分データベースから栄養成分値を自動計算し、パッケージの表示値との差異を検証。食品表示基準で定められた許容誤差(±20%)の範囲内かを確認。
表示順序チェック: 原材料が重量順に記載されているか、添加物の区分表示が正しいかをルールで検証。
レイヤー3: LLMによる表現チェック
ルールベースでは判定できない「表現の適切性」をLLMがチェックします。Claude 4.6 Sonnetを使用し、以下の観点で判定を行います。
- 強調表示の基準適合: 「カルシウムたっぷり」と表示する場合、100gあたり204mg以上(栄養強調表示基準)を満たしているか
- 健康関連表現: 「ダイエットに最適」のような表現が景表法や健康増進法に抵触しないか
- 文脈依存の判断: 「○○不使用」表記が適切か(そもそもその原材料が一般的に使われない食品で「不使用」を謳っていないか)
図2: AI審査パイプラインの全体構成 ― 入力からレポート出力まで
成果 ― 審査時間60%削減、表示ミスゼロ継続
A社の導入後12ヶ月の成果をまとめます。
| 指標 | 導入前 | 導入後 | 改善率 |
|---|---|---|---|
| 1商品あたり審査時間 | 平均3時間 | 平均1.2時間 | 60%削減 |
| 月間処理可能件数 | 15〜20件/人 | 35〜40件/人 | 2倍 |
| 表示ミス検出率 | 95%(人間のみ) | 99.5%(AI+人間) | 4.5pt向上 |
| 審査待ち遅延件数 | 月3〜4件 | 月0件 | 100%解消 |
| アレルゲン表示漏れ | 年1〜2件 | 0件(12ヶ月連続) | ゼロ達成 |
導入プロジェクトのタイムライン
| フェーズ | 期間 | 内容 |
|---|---|---|
| Phase 1 | 1ヶ月目 | アレルゲン照合のルール化。特定原材料8品目の自動照合を実装 |
| Phase 2 | 2〜3ヶ月目 | 栄養成分の自動計算・検証を追加。OCRパイプラインの精度調整 |
| Phase 3 | 4〜5ヶ月目 | LLMによる表現チェックを追加。既存商品200件でバックテスト |
| Phase 4 | 6ヶ月目〜 | 本番運用開始。マルチモーダルAIへの切り替え |
段階的導入のポイント
A社の成功要因は「一度にすべてを自動化しなかった」ことです。まずルールベースで自動化しやすい項目(アレルゲン照合・栄養計算)から始め、効果を確認してからLLMによる表現チェックに拡張しました。AI導入の6フェーズで推奨するMVP型アプローチの好例です。
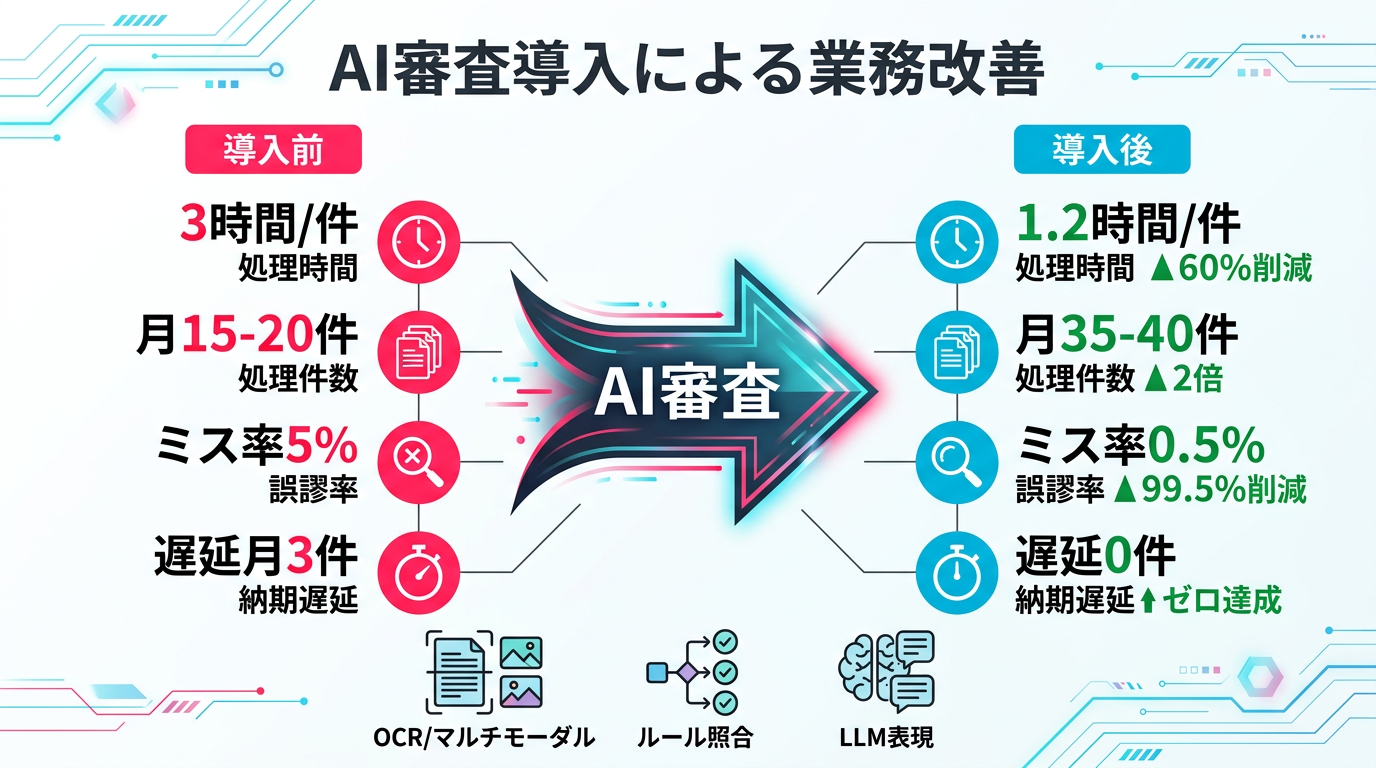 図3: 導入前後の主要指標比較 ― 審査時間60%削減と表示ミスゼロを達成
図3: 導入前後の主要指標比較 ― 審査時間60%削減と表示ミスゼロを達成
成功のポイント ― 法改正への自動追従設計
A社の導入で最も参考になるのは、法改正に対する「自動追従」の設計思想です。
ルールの外部化
審査ルールをアプリケーションコードから完全に分離し、YAML形式の設定ファイルで管理しています。
# アレルゲンルール設定例
allergens:
mandatory: # 特定原材料(表示義務)
- name: "えび"
aliases: ["エビ", "海老", "シュリンプ"]
category: "甲殻類"
- name: "かに"
aliases: ["カニ", "蟹", "クラブ"]
category: "甲殻類"
- name: "くるみ"
aliases: ["クルミ", "胡桃", "ウォルナッツ"]
category: "種実類"
# ... 他5品目
recommended: # 特定原材料に準ずるもの(表示推奨)
- name: "アーモンド"
aliases: ["アーモンドパウダー", "アーモンドミルク"]
# ... 他19品目法改正があった場合、この設定ファイルを更新するだけで判定基準が変わります。コード変更もデプロイも不要です。
RAGによる最新法令の取り込み
消費者庁のガイドライン文書やQ&Aをベクトルデータベースに取り込み、LLMの判定時に参照させるRAG(検索拡張生成)を実装しています。新しいガイドラインが公表されたら、ドキュメントを追加するだけでLLMの判断に反映されます。
2026年のマルチモーダルAIがもたらす次の進化
A社は現在、次のステップとしてパッケージデザインの段階で表示チェックを組み込む計画を進めています。
Gemini 3.1 Proの1Mトークンコンテキストウィンドウを活用すれば、パッケージのデザインデータ(AI/PDF)、原材料規格書、過去の審査結果、関連法令をすべて一度にLLMに投入し、包括的なチェックが可能になります。Claude 4.6 Opusのエージェント機能と組み合わせれば、複数の検証ステップを自律的に実行するAIエージェントが実現できます。
[将来構想: エージェント型表示審査]
デザインデータ入稿
├─ Agent 1: テキスト抽出 + 構造化
├─ Agent 2: アレルゲン照合 + コンタミチェック
├─ Agent 3: 栄養成分計算 + 数値検証
├─ Agent 4: 表現の法令適合チェック
└─ Supervisor: 結果統合 + レポート生成 + 重大度判定
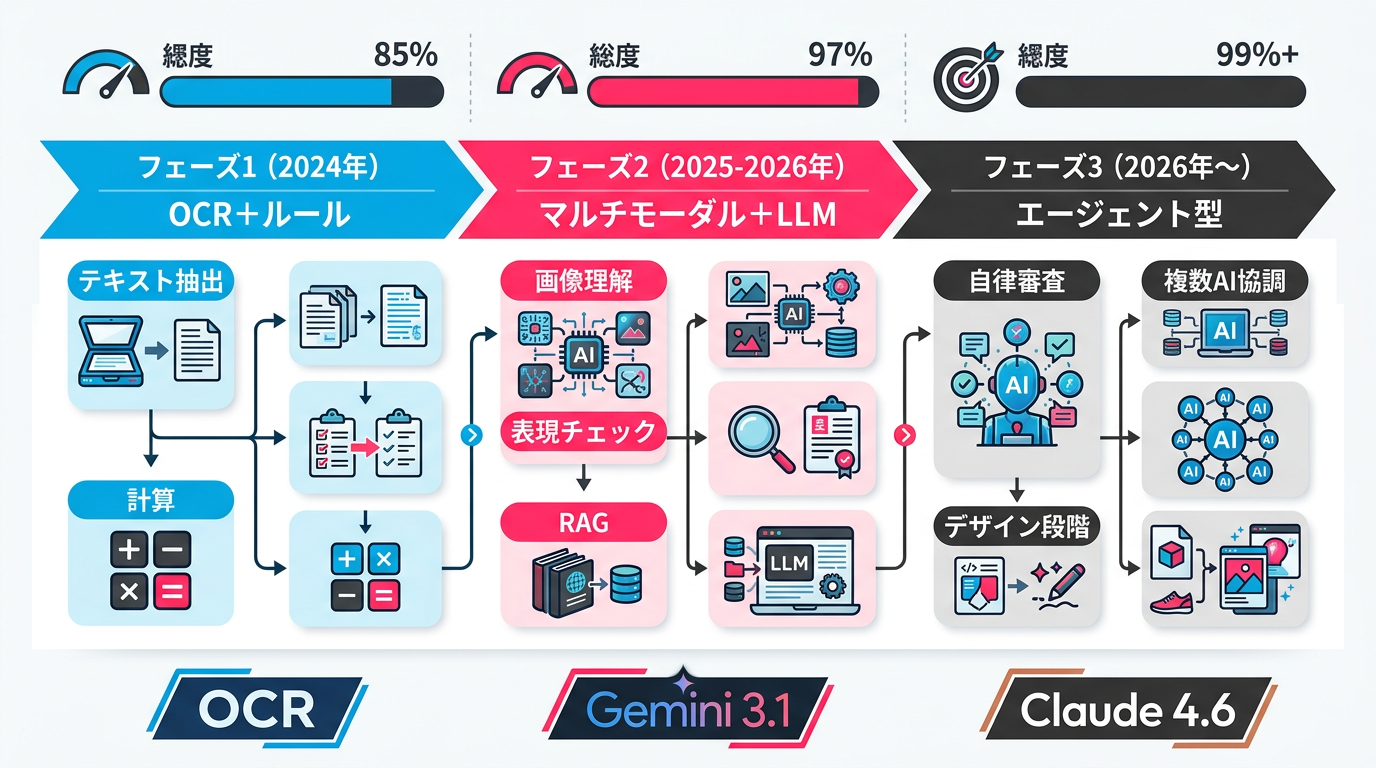 図4: 食品表示審査AIの進化 ― OCRからエージェント型へ
図4: 食品表示審査AIの進化 ― OCRからエージェント型へ
まとめ
食品メーカーの表示審査は、AIによる半自動化が最も効果を発揮する領域の一つです。
- ハイブリッド構成が最適解: マルチモーダルAI(テキスト抽出)+ルールベース(照合・計算)+LLM(表現チェック)の3層構造
- 段階的に導入する: アレルゲン照合→栄養計算→表現チェックの順で拡張
- 法改正への自動追従を設計する: ルールの外部化+RAGによる最新法令の取り込み
- マルチモーダルAIで精度を飛躍的に向上: OCR単体の85%からマルチモーダルAIの97%へ
食品表示審査は「ゼロミス」が要求される領域です。AIは人間のミスを補完し、人間はAIが判断できない文脈依存のケースに集中する。誤判定対応の設計で解説したエスカレーション体制と合わせて運用することで、表示ミスゼロの継続が現実的な目標になります。
よくある質問
食品表示審査のAI化にはどのくらいの期間がかかりますか?
ルールベースの基本チェック(アレルゲン照合・栄養成分の数値整合性)なら2〜3ヶ月で立ち上げ可能です。LLMによる表現チェック(強調表示の適切性、一括表示と原材料の整合性など)を含めると4〜6ヶ月が目安です。OCR精度の調整やパッケージデザインとの連携を含めると初期プロジェクト全体で6ヶ月程度を見込んでください。
アレルゲン表示のチェック精度はどのくらいですか?
ルールベースの照合(原材料リストと一括表示欄のアレルゲン表記の突合)は99%以上の精度が出せます。ただし、コンタミネーション(製造ライン由来の混入可能性)の表記チェックは文脈理解が必要なため、LLMとの組み合わせが有効です。2026年のClaude 4.6 Sonnetなら、原材料名からアレルゲンを推定し、表示漏れを検出する処理も高精度で行えます。
OCRで食品パッケージのテキストを読み取る際の課題は何ですか?
主な課題は3つあります。(1)背景の模様や色と文字の判別、(2)縦書きと横書きの混在、(3)小さいフォントサイズ(特に栄養成分表示)。2026年現在、Gemini 3.1 Proのようなマルチモーダルモデルを使えば、従来のOCRパイプラインを経由せず画像から直接テキストを理解できるため、これらの課題は大幅に緩和されます。
法改正への自動追従はどう実現しますか?
審査ルールをコードから分離し、JSONやYAML形式の設定ファイルとして管理します。食品表示法の改正時は設定ファイルを更新するだけでAIの判定基準が変わります。さらに、消費者庁のガイドライン文書をRAGで取り込み、LLMの判断に最新の法令情報を反映させる設計が効果的です。

この記事の著者
Naosy 編集部
レビュー・校正・審査プロセスの最適化に関する実践的なナレッジを発信しています。



