審査AIの品質モニタリング体制の作り方 ― ダッシュボード設計から改善サイクルまで
審査AIは導入して終わりではありません。精度の劣化を早期に検知し、継続的に改善するためのモニタリング体制の構築方法を、5つのKPI・ダッシュボード設計・アラート設計・週次改善サイクルの実践手法で解説します。
「AIを導入してから3ヶ月間、精度は維持できていますか?」――この質問に即答できる企業は驚くほど少ない。 私たちが支援してきた審査AI導入プロジェクトの多くで、「導入時に精度90%を確認した後、誰も精度を追跡していなかった」という状況に遭遇しました。半年後に調べてみると精度が75%まで低下していた、というケースは珍しくありません。
AIの判定精度は「導入時がピーク」です。審査基準の変更、入力データの傾向変化、LLMプロバイダーによるモデルアップデート――これらが少しずつ精度を蝕みます。審査AI導入の6フェーズで解説したPhase 6(定着化)を成功させるためには、品質モニタリング体制が不可欠です。
この記事では、審査AIの品質を継続的に監視し、劣化を早期に検知して改善するための実践的なモニタリング体制の構築方法を解説します。
「導入して終わり」が最大の失敗パターン
審査AIの品質が劣化する原因は大きく3つあります。
原因1: データドリフト ― 入力データの傾向が変わる
審査AIに入力されるデータの分布は、時間とともに変化します。広告審査なら新しい広告フォーマットやトレンドの出現、文書審査なら法改正に伴う表現の変化が該当します。AIが学習時(またはプロンプト設計時)に想定していなかったパターンが増えると、判定精度が低下します。
原因2: コンセプトドリフト ― 正解の基準自体が変わる
審査基準そのものが変更される場合です。たとえば景表法のガイドライン改定で、以前はOKだった表現がNGになるケース。AIは旧基準のまま判定を続けるため、人間の判断とのズレが生じます。ルールベース×LLMのハイブリッド設計でルール側を更新しても、LLM側のプロンプトが旧基準のままだと不整合が起きます。
原因3: モデルドリフト ― AIモデル自体が変わる
LLMプロバイダーがモデルをアップデートすることで、同じプロンプトでも出力が変わることがあります。2026年現在、Claude 4.6やGPT-5.4は頻繁にマイナーアップデートが行われており、「昨日まで正しく判定していたのに、今日から判定が変わった」という事象が起こりえます。モデルバージョンの固定(ピニング)で回避できますが、セキュリティパッチや機能改善を受けられなくなるトレードオフがあります。
精度劣化の平均速度
私たちの経験では、モニタリングなしの審査AIは導入後6ヶ月で精度が5〜15ポイント低下します。月1回のチェックだけでも、この劣化を半分以下に抑えられます。
モニタリングすべき5つのKPI
審査AIの品質を監視するために、以下の5つのKPIを設定します。AI審査モデルの評価指標で解説している精度・再現率・F1スコアの概念を、運用モニタリングに適用した形です。
KPI 1: 正答率(Accuracy)
AIの判定と人間の最終判断の一致率です。サンプリングで測定します。全件を人間がダブルチェックするのが理想ですが、コストが高いため、1日の判定件数の5〜10%をランダムサンプリングして人間が確認する方法が実用的です。週次で集計し、ベースラインからの低下を追跡します。
KPI 2: エスカレーション率
AIが判定できず人間にエスカレーションした件数の割合です。エスカレーション率が急上昇した場合、AIの確信度が全体的に低下している(=判断に迷うケースが増えている)ことを示します。通常は10〜20%の範囲に収まるべきで、30%を超えたら原因調査が必要です。
KPI 3: 処理時間(レイテンシ)
1件あたりのAI判定にかかる時間です。LLM APIの応答時間はプロバイダー側の負荷によって変動するため、異常な増加はシステム障害の予兆になります。また、処理時間が業務のSLA(サービスレベル合意)を超えていないかの確認にも使います。
KPI 4: 確信度分布
AIが出力する確信度スコアの分布を追跡します。正常な状態では、確信度の高い判定(90%以上)が大部分を占めます。確信度の中間領域(50〜70%)に判定が集中し始めたら、データドリフトの兆候です。
KPI 5: 誤判定パターン分布
AIの誤判定を「偽陽性(問題ないのにNG判定)」と「偽陰性(問題があるのにOK判定)」に分類し、その比率と傾向を追跡します。特定のカテゴリやパターンに誤判定が集中していないかを確認し、集中している場合はそのカテゴリに特化した改善策を講じます。
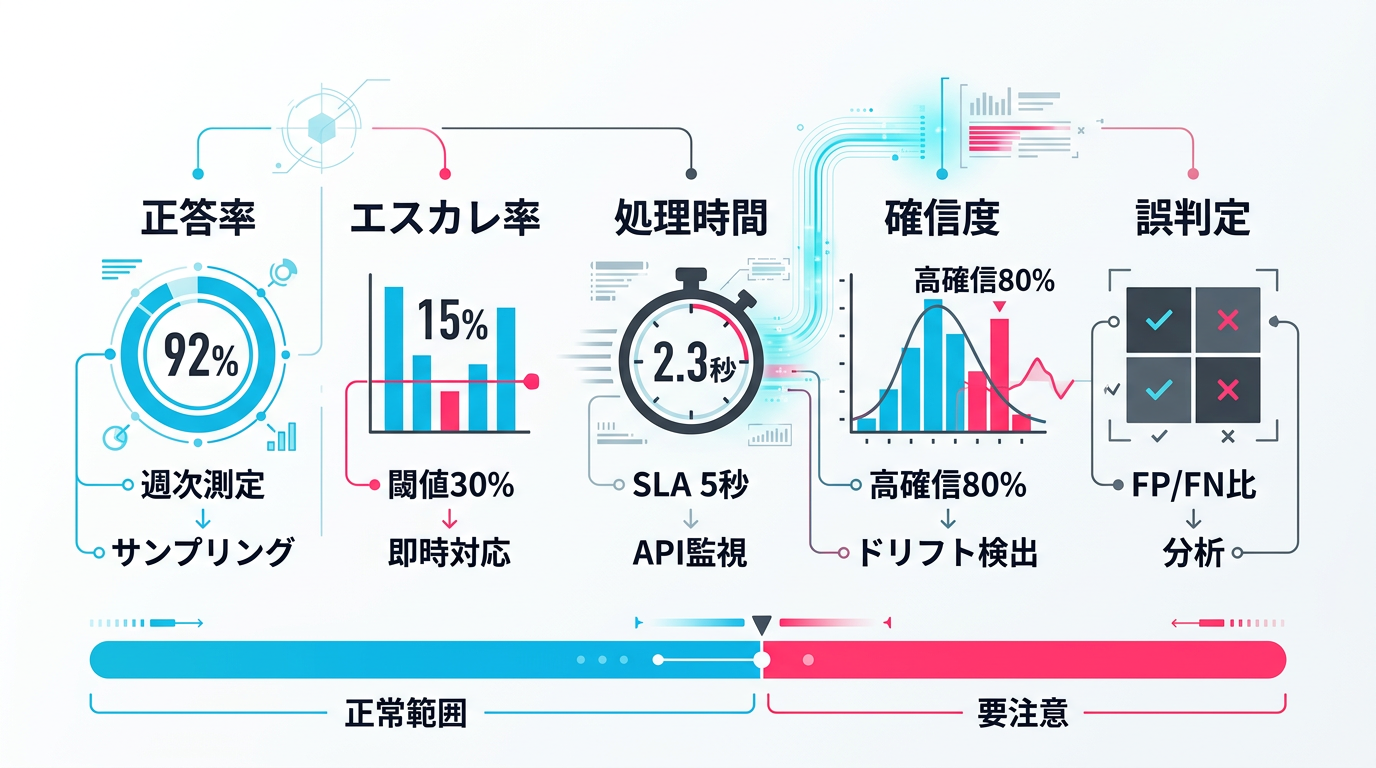 図2: 審査AI品質モニタリングの5つのKPI
図2: 審査AI品質モニタリングの5つのKPI
ダッシュボードの設計テンプレート
5つのKPIを日常的に確認するためのダッシュボードを設計します。既存のBIツール(Metabase、Redash、Looker、Grafana)で構築できますが、LLMベースの審査AIには専用ツールを組み合わせると効果的です。
ダッシュボードの3階層構造
ダッシュボードは「概要→詳細→調査」の3階層で設計します。
第1階層: エグゼクティブビュー(週次確認)
経営層やプロジェクトオーナーが1分で状況を把握できるビューです。5つのKPIの現在値と、直近4週間のトレンドをシンプルなグラフで表示します。各KPIに「正常(緑)」「注意(黄)」「異常(赤)」の信号をつけ、どこに問題があるかを即座に判断できるようにします。
第2階層: オペレーションビュー(日次確認)
運用チームが毎日チェックするビューです。KPIの日次推移に加えて、カテゴリ別の精度内訳、エスカレーションされた案件の一覧、処理時間のパーセンタイル分布(P50、P95、P99)を表示します。
第3階層: 調査ビュー(異常時のドリルダウン)
第1・第2階層で異常を検知した際に、原因を特定するためのビューです。個別の判定ログを検索・フィルタリングでき、特定のカテゴリや時間帯に絞り込んで誤判定のパターンを分析できます。
LLMOps専用ツールの活用
2026年現在、LLMベースの審査AIのモニタリングには、従来のMLOpsツールに加えてLLMOps専用ツールが有効です。
Langfuse: オープンソースのLLMオブザーバビリティツール。プロンプトのバージョン管理、入出力のトレース記録、コスト追跡、品質スコアの記録が可能です。セルフホスト版があるため、審査データを外部に出せない組織でも利用できます。
LangSmith: LangChainが提供するLLMアプリケーション開発プラットフォーム。プロンプトの実行トレース、評価データセットの管理、A/Bテストの実行を一元管理できます。
これらのツールは、従来のBIツールでは難しい「プロンプトバージョンごとの精度比較」や「入出力トークン数とコストの追跡」を簡単に実現できます。Claude 4.6 SonnetやGPT-5.4のAPI呼び出しをトレースし、どのプロンプトバージョンが最も高い精度を出しているかを可視化する使い方が一般的です。
アラート設計 ― 何が起きたら誰に通知するか
モニタリングの仕組みができたら、次は異常を検知したときに「誰に」「何を」通知するかを設計します。アラート設計で最も重要なのは、ノイズ(不要なアラート)と見逃し(必要なアラートの未発報)のバランスです。
アラートの3段階設計
Level 1: 情報通知(Slack/メール通知)
日常的な変動の範囲内だが、トレンドとして注意が必要なケース。正答率がベースラインから2ポイント以上低下、エスカレーション率が通常の1.5倍を超過、といった閾値を設定します。運用チームのSlackチャンネルに自動通知し、翌日の確認事項に追加します。
Level 2: 対応要請(即時通知+担当者アサイン)
業務に影響が出始めている、または出る可能性が高いケース。正答率がベースラインから5ポイント以上低下、処理時間がSLAの80%に到達、特定カテゴリの誤判定が集中、といった閾値です。運用リーダーに即時通知し、24時間以内の原因分析と対策立案を要求します。
Level 3: 緊急対応(エスカレーション+フォールバック発動)
審査の信頼性に重大な問題が生じているケース。正答率がベースラインから10ポイント以上低下、APIエラーが連続発生、LLMの出力形式が崩壊(JSON解析エラー多発)。プロジェクトオーナーにエスカレーションし、必要に応じてAI審査を一時停止して人間による全件チェックに切り替えるフォールバック手順を発動します。
アラート疲れを防ぐ工夫
アラートが多すぎると、運用チームが通知を無視するようになります(アラート疲れ)。これを防ぐために以下の工夫を入れます。
- 集約ルール: 同一原因の複数アラートは1つにまとめる。「カテゴリAで精度低下」「カテゴリAでFP増加」「カテゴリAでエスカレーション増加」は1つの「カテゴリA異常」アラートに統合
- クールダウン期間: 同じアラートが解消されるまで再発報しない。1時間のクールダウンを設定すると、連続発報を防げる
- 定期的な閾値見直し: 月次でアラートの発報回数と対応率を確認し、不要なアラートは閾値を調整するか廃止する
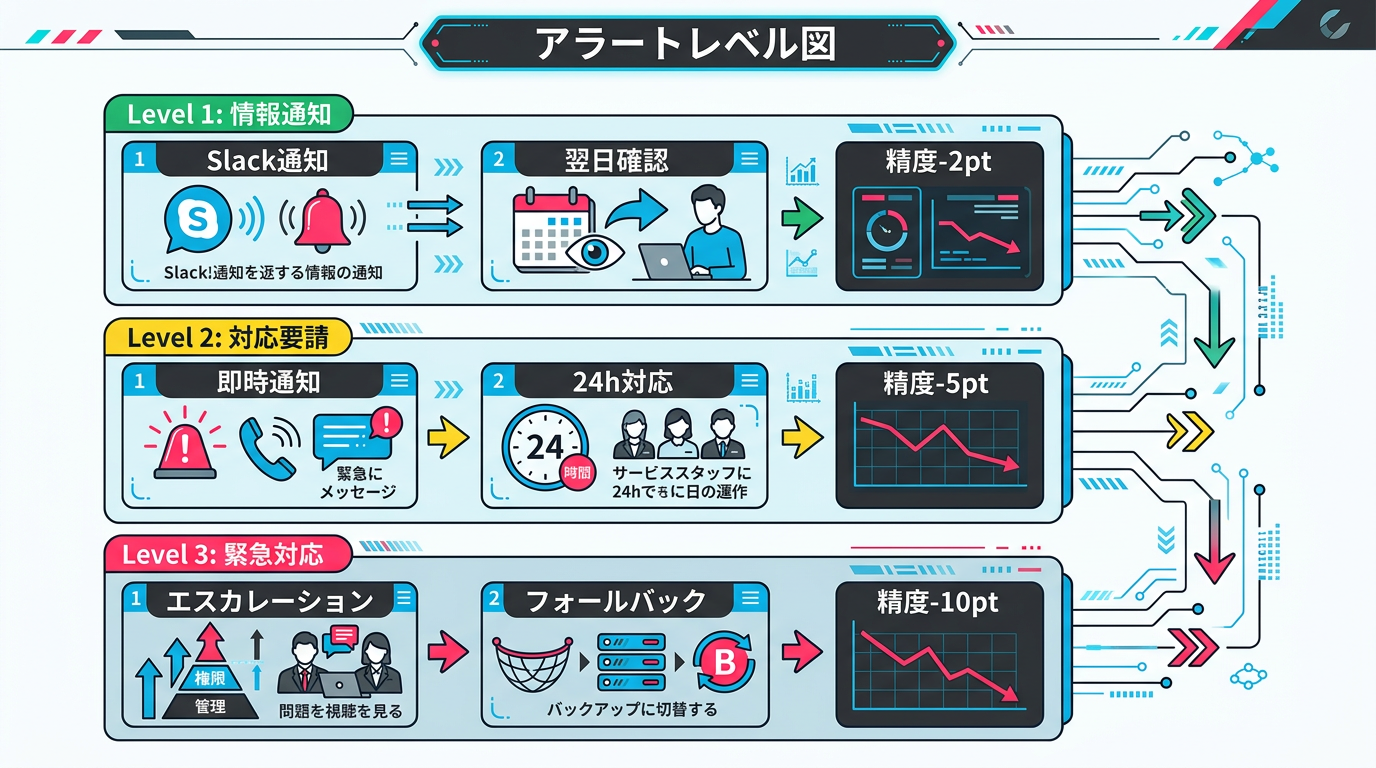 図3: アラートの3段階設計 ― ノイズと見逃しのバランス
図3: アラートの3段階設計 ― ノイズと見逃しのバランス
ドリフト検出 ― 精度劣化の兆候を早期に捉える
KPIの数値が明確に悪化する前に、ドリフトの兆候を検出する仕組みを構築します。
入力ドリフトの検出
審査AIに入力されるテキストの傾向が変化していないかを監視します。2026年のLLMを使った検出方法が効果的です。
方法1: 入力テキストのエンベディング(数値ベクトル表現)分布を追跡する
入力テキストをエンベディングに変換し、その分布の変化を統計的に検出します。過去30日間の入力分布をベースラインとし、直近7日間の分布との乖離(KLダイバージェンスやコサイン類似度で測定)が閾値を超えたらアラートを発報します。
方法2: Claude 4.6 Sonnetで入力傾向を要約させる
より直感的な方法として、直近1週間の入力テキストのサンプルをLLMに投入し、「過去と比べて新しく出現したパターンや表現はあるか」を分析させます。LLMの言語理解能力を活かした質的なドリフト検出です。統計的な手法と組み合わせると、数値では捉えにくい意味的なドリフトも検出できます。
出力ドリフトの検出
AIの出力傾向が変化していないかを監視します。
- OK/NG判定の比率変化: OK/NG比率が過去の平均から大きく逸脱していないかを確認。急にNG率が上がった場合、入力の傾向変化か、AIの判定基準の変化か、どちらかを切り分ける
- 確信度スコアの分布変化: 確信度の平均値や分散が変化していないかを追跡。確信度が全体的に低下している場合、AIが「判断に迷うケース」が増えていることを示す
- 出力フォーマットの整合性: LLMの出力がJSON形式を維持しているか、必須フィールドが欠落していないか。モデルアップデート後に出力形式が崩れることがある
週次改善サイクルの回し方
モニタリングとアラートの仕組みだけでは、品質は改善しません。検知した問題を改善アクションにつなげる週次改善サイクルを運用に組み込みます。
週次品質レビューミーティング(30分)
毎週1回、30分間の品質レビューミーティングを開催します。
参加者: 運用リーダー、審査チーム代表(1〜2名)、エンジニア代表(1名)
アジェンダ:
- 5分: ダッシュボードの5 KPIの確認(エグゼクティブビューを共有)
- 10分: 先週のアラート対応の振り返りと残課題の確認
- 10分: 誤判定サンプルのレビュー(3〜5件を詳細に確認し、原因を特定)
- 5分: 来週の改善アクションの決定とアサイン
このミーティングの目的は「改善アクションを1つ決めて実行すること」です。完璧な分析を目指すのではなく、小さな改善を毎週積み重ねることが重要です。
改善アクションの4パターン
週次レビューで検出された問題に対して、以下の4パターンで対応します。
- プロンプト修正: 特定のカテゴリで誤判定が集中している場合、プロンプトにそのカテゴリの判定基準を追加・修正する。即日対応可能
- ルール追加: LLMが一貫してNGと判定するパターンが見つかった場合、ルールベースに追加してLLMの負荷を減らす。1〜3日で対応
- サンプルデータ追加: Few-Shot(少数の例示)で改善できるケース。正解例を3〜5件追加してプロンプトに組み込む。即日対応可能
- エスカレーション基準調整: 確信度の閾値を調整し、エスカレーション率と精度のバランスを最適化する。効果検証に1〜2週間
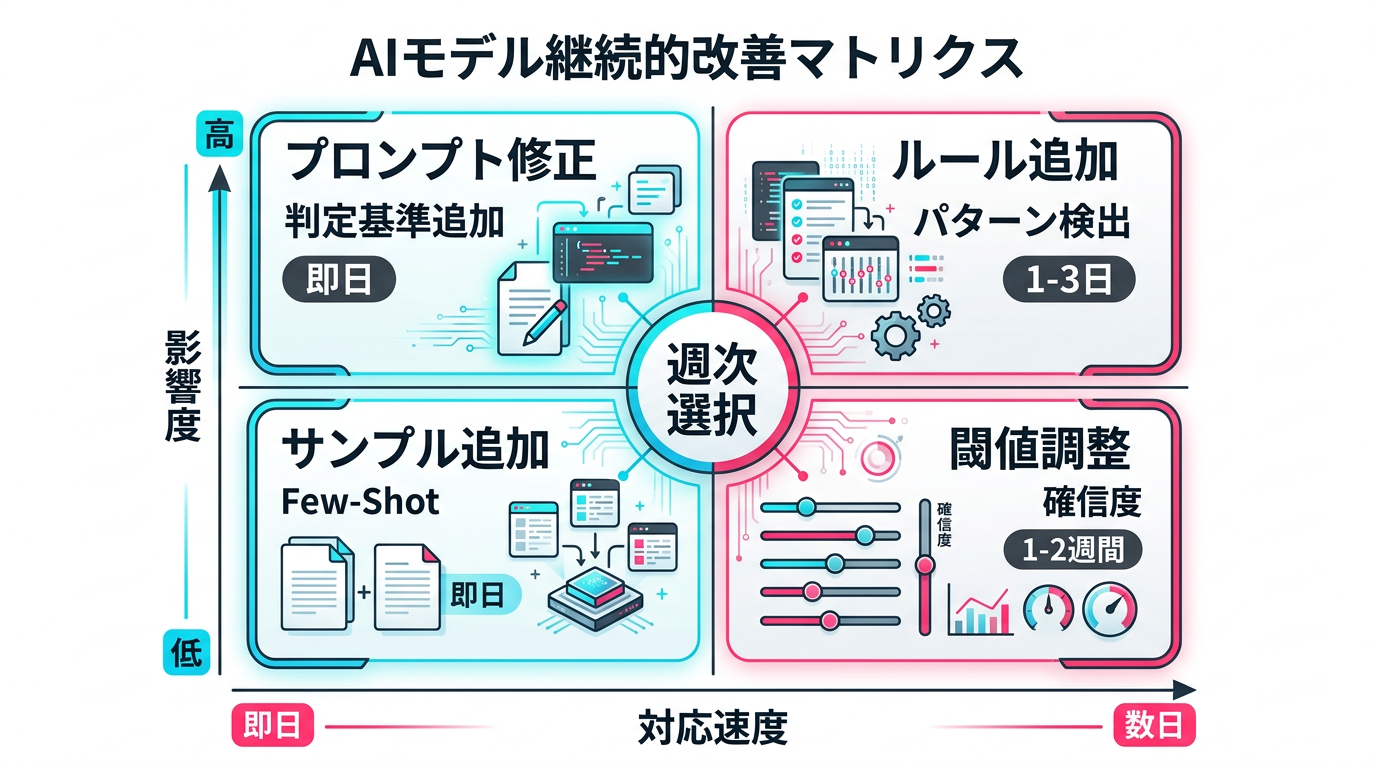 図4: 改善アクションの4パターン ― 影響度と対応速度で選ぶ
図4: 改善アクションの4パターン ― 影響度と対応速度で選ぶ
まとめ
審査AIの品質モニタリングは、「導入の成功」を「継続的な成功」に変えるための仕組みです。
- 5つのKPIを設定する: 正答率、エスカレーション率、処理時間、確信度分布、誤判定パターン分布の5つを週次で追跡
- ダッシュボードは3階層で設計: エグゼクティブビュー(週次)、オペレーションビュー(日次)、調査ビュー(異常時)の3段階で情報を整理
- アラートは3段階で設計: 情報通知→対応要請→緊急対応の3レベルで、ノイズと見逃しのバランスを取る
- 週次改善サイクルを回す: 30分のレビューミーティングで改善アクションを1つ決め、毎週実行する
次のアクションとして、自社の審査AIの「導入時の精度」を確認してください。それがベースラインになります。ベースラインが分からなければ、今週から1週間分のサンプリング評価を実施し、現在の精度を測定することから始めましょう。
よくある質問(FAQ)
審査AIのモニタリングはなぜ必要ですか?
AIの判定精度は時間とともに劣化します。審査基準の変更、入力データの傾向変化、LLMのモデルアップデートなどが原因です。モニタリングなしでは精度劣化に気づかず、誤判定が累積して業務品質が低下します。導入後3ヶ月以内にモニタリング体制を構築することを推奨します。
最低限モニタリングすべき指標は何ですか?
最低限必要なのは、精度(正答率)、処理時間、エスカレーション率の3指標です。精度は人間の二次審査結果との一致率で測定し、週次で追跡します。処理時間の異常な増加はシステム障害の予兆になり、エスカレーション率の急増はAIの判断が不安定になっているサインです。
データドリフトとは何ですか?
AIに入力されるデータの分布が、学習時やプロンプト設計時の想定から変化することです。たとえば広告審査AIの場合、新しい広告フォーマットや表現トレンドの変化がデータドリフトにあたります。ドリフトが発生するとAIの精度が劣化するため、定期的な検出と対応が必要です。
モニタリングツールは何を使えばいいですか?
LLMベースの審査AIにはLangfuseやLangSmithが適しています。プロンプトのバージョン管理、出力品質のトラッキング、コスト監視が一元管理できます。既存のBI基盤(Metabase、Redash、Looker)がある組織なら、それにAI用のダッシュボードを追加する形が最もスムーズです。

この記事の著者
Naosy 編集部
レビュー・校正・審査プロセスの最適化に関する実践的なナレッジを発信しています。



