審査ログ活用の実践ガイド ― データドリブンな品質改善サイクルの回し方
審査AIが蓄積するログは品質改善の宝の山です。ログスキーマの設計、NG理由の自動分類、LLMを使ったインサイト抽出、週次改善ミーティングの運営まで、審査ログをアクションにつなげる実践手法を解説します。
「毎月10万件のAI判定ログが蓄積されているのに、誰もそのデータを見ていない」――審査AI導入後の企業で、驚くほど多く見られる光景です。 ログは「記録する」だけでは意味がありません。ログからパターンを発見し、改善アクションにつなげて初めて価値が生まれます。
審査AIのログには、品質改善に直結する情報が詰まっています。どのカテゴリで誤判定が多いか、どの時期に精度が劣化したか、人間がAIの判定を覆したケースにどんなパターンがあるか。これらの情報を体系的に分析し、改善サイクルを回す仕組みを構築すれば、審査AIの精度は導入後も継続的に向上します。
この記事では、審査ログをデータドリブンな品質改善に活かすための実践手法を、ログ設計から分析、改善アクション、効果検証までの一連のサイクルで解説します。
なぜ審査ログが「ただの記録」で終わるのか
多くの組織で審査ログが活用されない理由は3つあります。
理由1: ログの設計が分析を想定していない
「判定結果を記録する」だけのログ設計では、後から分析しようとしても必要な情報が足りません。確信度スコアが記録されていない、NG理由がフリーテキストで統一されていない、プロンプトバージョンと紐づいていない。こうした設計不備が、ログ分析を困難にしています。
理由2: 分析する人と分析する時間が確保されていない
審査チームは日常の審査業務で手一杯であり、「ログを分析して改善する」時間が確保されていません。審査AIの品質モニタリングで解説した週次改善ミーティングの枠組みがなければ、ログ分析は「余裕があればやる」タスクに留まり、永遠に実施されません。
理由3: ログから何を見るべきか分からない
ログが蓄積されていても、「何を分析すればいいか分からない」という声は多いです。KPIが定義されていない、分析の手法が分からない、ツールが使えない。この記事では、この問題を解決するための具体的な手法を提供します。
ログスキーマの設計 ― 後から分析できるデータを記録する
ログ設計の原則は「後から分析したい軸で切れるように記録する」ことです。以下の項目を構造化ログ(JSON形式)で記録します。
必須フィールド(7項目)
- request_id: 一意の判定ID。他のシステムとの紐付けに使用
- timestamp: 判定日時(ISO 8601形式)
- input_hash: 入力テキストのハッシュ値。同一入力の再判定を検出するため
- verdict: AI判定結果(OK / NG / ESCALATED)
- confidence: 確信度スコア(0.0〜1.0)
- processing_time_ms: 処理時間(ミリ秒)
- model_version: 使用したLLMモデルのバージョン(例: claude-sonnet-4-6-20260301)
推奨フィールド(5項目)
- ng_reason_code: NG判定の理由コード(事前定義したカテゴリ)
- ng_reason_text: NG理由の詳細テキスト(AIが生成した説明文)
- prompt_version: 使用したプロンプトのバージョン
- input_category: 入力データのカテゴリ(広告/文書/メール等)
- token_count: 入出力トークン数(コスト追跡用)
オーバーライドフィールド(人間が判定を覆した場合)
- human_verdict: 人間の最終判定
- override_reason: 覆した理由
- reviewer_id: 審査者ID
- review_timestamp: レビュー日時
オーバーライド記録は改善の宝庫
人間がAIの判定を覆したケースは、AIが間違えたケースの直接的な証拠です。オーバーライドの記録は、ログ分析で最も価値の高いデータです。必ず記録してください。
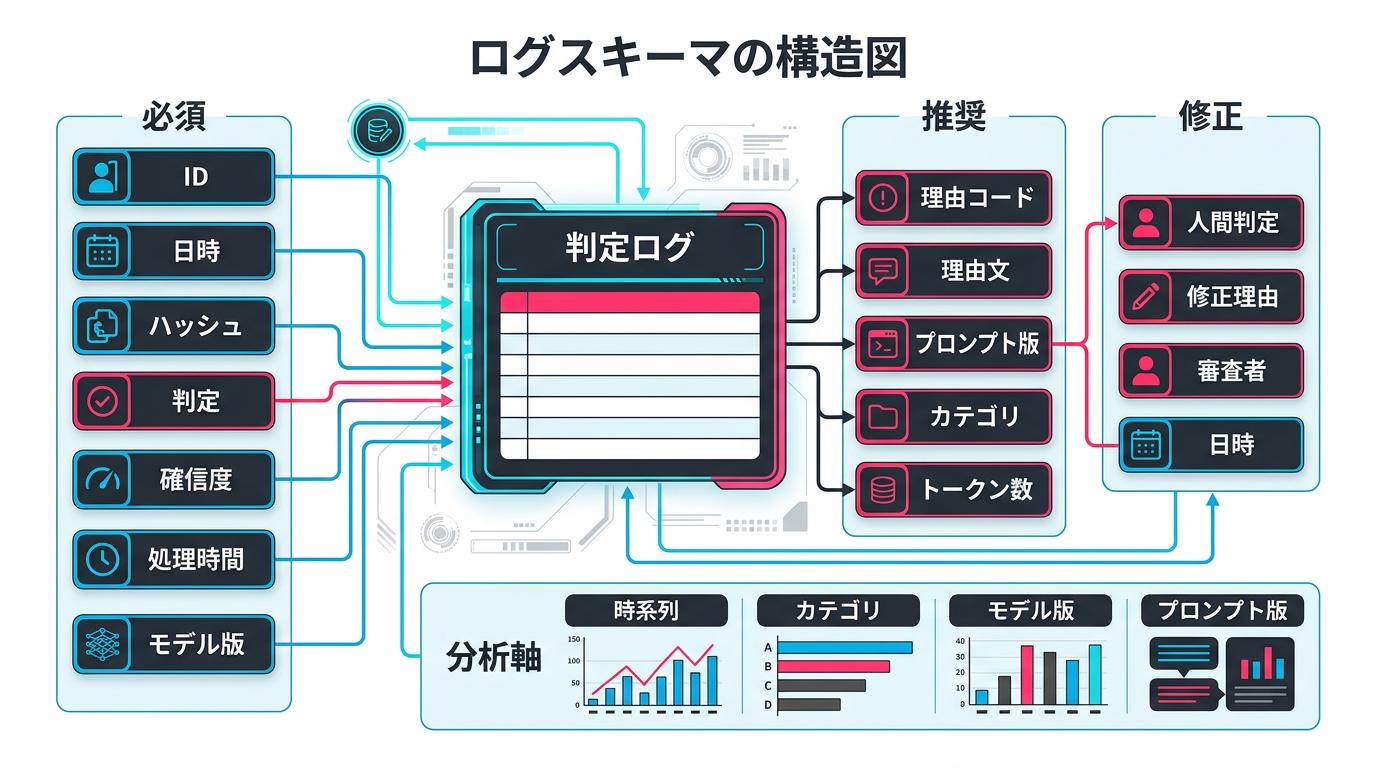 図2: 審査ログスキーマ ― 後から分析できるデータ設計
図2: 審査ログスキーマ ― 後から分析できるデータ設計
NG理由の分類と傾向分析
ログが蓄積されたら、最も価値の高い分析は「NG理由の分類と傾向分析」です。
LLMを使ったNG理由の自動分類
AIが出力するNG理由テキストを、事前定義したカテゴリに自動分類します。2026年現在、最も実用的な方法はLLMによる分類です。
Claude 4.6 Sonnetに以下のようなプロンプトを与え、NG理由を分類させます。
「以下のNG理由テキストを、次のカテゴリのいずれかに分類してください:表現違反(禁止表現の使用)、数値不整合(価格・数量の誤り)、形式不備(必須項目の欠落)、コンプライアンス(法令違反の恐れ)、品質基準(トーン・スタイルの不適合)、その他」
この分類をバッチ処理で実行し、ng_reason_codeフィールドに格納します。分類精度は95%以上が期待でき、手作業での分類に比べて100倍以上の速度で処理できます。
新しいNGパターンの自動発見
事前定義したカテゴリに当てはまらない「その他」が増えた場合、新しいNGパターンが出現している可能性があります。エンベディング(テキストをベクトルに変換する手法)を使ったクラスタリングで、未知のパターンを自動的に発見できます。
「その他」に分類されたNG理由テキストをエンベディングに変換し、似たテキストのグループ(クラスタ)を自動生成します。各クラスタの代表的なテキストをLLMに要約させれば、「新しく出現したNGパターン」の概要が人間に分かりやすい形で得られます。
インサイト抽出 ― ログから改善アクションを導く
分類・集計されたログデータから、具体的な改善アクションにつながるインサイトを抽出する方法を3つ紹介します。
インサイト1: カテゴリ別精度の変化を追跡する
NG理由カテゴリ別にAIの精度(人間の最終判定との一致率)を週次で追跡します。全体の精度が安定していても、特定のカテゴリで精度が低下していることがあります。たとえば「表現違反」の精度は維持できているが、「コンプライアンス」カテゴリの精度が3週連続で低下している、といったパターンです。
このパターンが見つかった場合、そのカテゴリに関するプロンプトの改善が即座にアクションになります。ルールベース×LLMのハイブリッド設計の考え方を活用し、そのカテゴリをルールベースに移行することも検討します。
インサイト2: オーバーライドパターンを分析する
人間がAIの判定を覆したケース(オーバーライド)を集中的に分析します。オーバーライドのパターンは、AIの弱点を直接示しています。
分析の切り口は3つです。
- カテゴリ別オーバーライド率: どのカテゴリでAIの判定が最も多く覆されているか
- 方向別分析: AI→OK→人間がNG(偽陰性、見逃し)と、AI→NG→人間がOK(偽陽性、過検出)のどちらが多いか
- 確信度との相関: オーバーライドされたケースの確信度分布。高確信で覆されたケースは「AIの判断基準に根本的な問題がある」ことを示す
インサイト3: LLMで根本原因を分析する
2026年のLLMは、ログデータの分析にも強力なツールになっています。誤判定のサンプルをまとめてClaude 4.6 Opusに投入し、「これらの誤判定に共通するパターンは何か」「どのような改善がこれらのエラーを防げるか」を分析させます。
人間が数時間かけて行う誤判定のパターン分析を、LLMは数分で実行できます。ただし、LLMの分析結果は仮説として扱い、人間が検証した上で改善アクションに移すことが重要です。
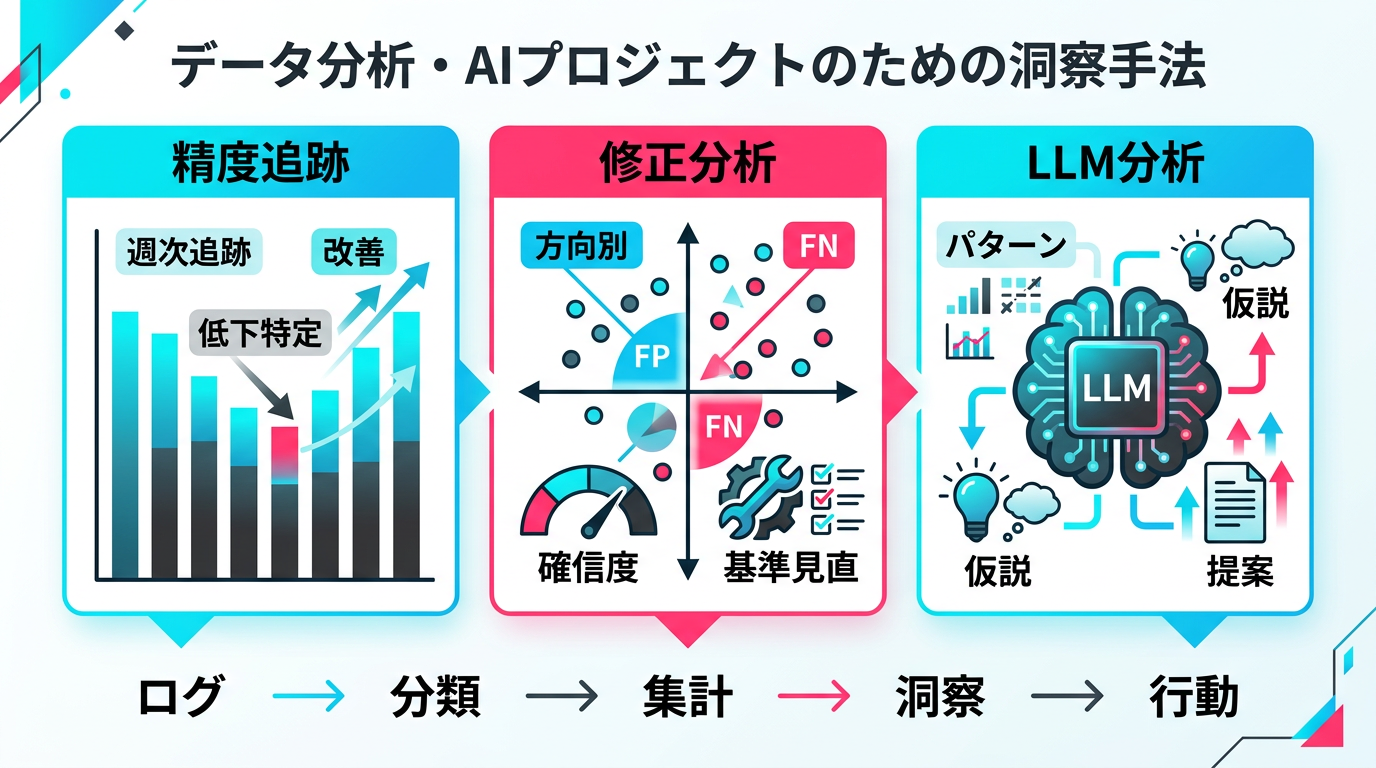 図3: ログからインサイトを抽出する3つの手法
図3: ログからインサイトを抽出する3つの手法
改善効果の計測方法
改善アクションを実施したら、その効果を数値で検証します。「改善した気がする」ではなく、データで効果を証明する仕組みを設計します。
Before / After比較の設計
改善アクション(プロンプト修正、ルール追加など)を実施する前に、必ず「Before」のデータを記録します。改善前1週間のKPI(正答率、FP率、FN率、エスカレーション率)をベースラインとし、改善後1〜2週間のKPIと比較します。
重要なのは、比較条件を揃えることです。入力データの分布が大きく変わった期間(年末年始、キャンペーン期間など)は比較対象として不適切です。可能であれば、同一期間内でA/Bテスト(改善版と旧版を並行で実行して比較)を行うのが最も信頼性の高い検証方法です。
改善アクションの投資対効果
改善アクションごとに「投入した時間」と「得られた精度向上」を記録し、費用対効果を追跡します。この記録が蓄積されると、「プロンプトの改善は平均2時間の作業で精度1.5ポイントの向上が見込める」「ルール追加は平均4時間の作業で特定カテゴリの精度5ポイントの向上が見込める」といった経験則が得られます。
ログ駆動の週次改善ミーティング
ログ分析の結果を改善アクションにつなげるための、週次ミーティングの具体的な進め方を紹介します。
アジェンダ(30分)
- 5分: 今週のKPIサマリー確認(ダッシュボードを画面共有)
- 5分: 先週の改善アクションの効果検証(Before/After比較)
- 10分: 今週の誤判定サンプル深掘り(3〜5件を選び、原因と対策を議論)
- 5分: 新しく出現したNGパターンの確認(クラスタリング結果のレビュー)
- 5分: 来週の改善アクション決定(1つに絞り、担当者と期限を決める)
成功のためのルール
- 改善アクションは毎週1つだけ: 複数のアクションを同時に実施すると効果の切り分けができない
- 必ずデータで語る: 「最近精度が落ちている気がする」ではなく「先週の正答率は89.3%で、前週の91.2%から1.9ポイント低下」と具体的に
- アクションには期限と担当者を必ずつける: 「来週までにカテゴリAのプロンプトを改善する。担当は○○さん」
まとめ
審査ログは「記録して終わり」ではなく、品質改善の最強のデータソースです。
- ログスキーマは分析を想定して設計: 必須7項目+推奨5項目+オーバーライド4項目を構造化ログで記録
- NG理由はLLMで自動分類: Claude 4.6 Sonnetで95%以上の精度で分類し、新パターンはクラスタリングで自動発見
- 3つの切り口でインサイトを抽出: カテゴリ別精度変化、オーバーライドパターン、LLM根本原因分析
- 効果は数値で証明: Before/After比較とA/Bテストで改善効果を定量的に検証
- 週次30分のミーティングで改善を回す: 毎週1つの改善アクションを決め、翌週に効果を検証
次のアクションとして、自社の審査AIのログに「確信度スコア」と「オーバーライド記録」が含まれているか確認してください。この2つのフィールドがなければ、ログスキーマの更新を最初のステップにしましょう。
よくある質問(FAQ)
審査ログには何を記録すべきですか?
最低限必要なのは、入力データのID、AI判定結果(OK/NG)、確信度スコア、NG理由コード、処理時間、使用したモデルバージョン、プロンプトバージョンの7項目です。加えて、人間がAIの判定を覆した場合のオーバーライド記録と、その理由を記録しておくと改善に直結するデータになります。
ログ分析にはどんなツールが必要ですか?
大規模なシステムでなければ、既存のBI基盤(Metabase、Redash、Looker)で十分です。ログの保存先はPostgreSQLやBigQueryが一般的です。LLMベースの審査AIであれば、LangfuseやLangSmithを使うとプロンプトバージョンとの紐付けが簡単になります。
NG理由の自動分類はどうすればいいですか?
2026年現在、最も実用的なのはLLMによる分類です。Claude 4.6 SonnetにNG理由のテキストを入力し、事前に定義したカテゴリ(表現違反、数値不整合、形式不備など)に分類させます。エンベディングベースのクラスタリングと組み合わせると、事前に想定していなかった新しいNGパターンの発見にも使えます。
どのくらいの頻度でログ分析をすべきですか?
週次の簡易分析と月次の詳細分析の2段階を推奨します。週次では5つのKPIの確認と誤判定サンプルのレビュー(30分)、月次ではNG理由の傾向変化、カテゴリ別精度の推移、改善アクションの効果検証を実施します(60分)。

この記事の著者
Naosy 編集部
レビュー・校正・審査プロセスの最適化に関する実践的なナレッジを発信しています。



